3.8 排序算法
3.8 排序算法
评价排序算法的指标
1. 执行效率
在分析排序算法的时间复杂度时,要分别给出最好情况、最坏情况、平均情况下的时间复杂度。
2. 内存消耗
算法的内存消耗可以通过空间复杂度来衡量。
空间复杂度是 O(1)的排序算法,称为原地排序(Sorted in place)。
3. 稳定性
稳定性是指,如果待排序的序列中存在值相等的元素,经过排序之后,相等元素之间原有的先后顺序不变。
很多数据结构和算法课程,在讲排序的时候,都是用整数来举例,但在真正软件开发中,我们要排序的往往不是单纯的整数,而是一组对象,我们需要按照对象的某个 key 来排序。当需要先按 key1 排序,key1 值相同的再按照 key2 排序时,就需要使用稳定的排序算法。
常见排序算法的各项指标如下:
| 排序算法 | 平均时间复杂度 | 最好情况 | 最坏情况 | 空间复杂度 | 排序方式 | 稳定性 |
|---|---|---|---|---|---|---|
| 冒泡排序 | O(n^2) | O(n) | O(n^2) | O(1) | in-place | 稳定 |
| 选择排序 | O(n^2) | O(n^2) | O(n^2) | O(1) | in-place | 不稳定 |
| 插入排序 | O(n^2) | O(n) | O(n^2) | O(1) | in-place | 稳定 |
| 希尔排序 | O(nlogn) | O(nlog^2n) | O(nlog^2n) | O(1) | in-place | 不稳定 |
| 归并排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(n) | out-place | 稳定 |
| 快速排序 | O(nlogn) | O(nlogn) | O(n^2) | O(logn) | in-place | 不稳定 |
| 堆排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(1) | in-place | 不稳定 |
| 桶排序 | O(n+k) | O(n+k) | O(n^2) | O(n+k) | out-place | 稳定 |
| 计数排序 | O(n+k) | O(n+k) | O(n+k) | O(k) | out-place | 稳定 |
| 基数排序 | O(n*k) | O(n*k) | O(n*k) | O(n+k) | out-place | 稳定 |
冒泡排序(Bubble Sort)
冒泡排序只会操作相邻的两个数据。每次冒泡操作都会对相邻的两个元素进行比较,看是否满足大小关系要求。如果不满足就让它俩互换。一次冒泡会让至少一个元素移动到它应该在的位置,重复 n 次,就完成了 n 个数据的排序工作。 

function bubbleSort(arr) {
let n = arr.length;
for (let i = 0; i < n; i++) {
for (let j = 0; j < n - 1 - i; j++) {
if (arr[j] > arr[j + 1]) {
// 相邻数据比较
let temp = arr[j + 1]; // 交换
arr[j + 1] = arr[j];
arr[j] = temp;
}
}
}
return arr;
}
冒泡排序的平均时间复杂度是 O(n^2),冒泡的过程只涉及相邻数据的交换操作,只需要常量级的临时空间,所以它的空间复杂度为 O(1),是一个原地排序算法。相同大小的数据在排序前后不会改变顺序,所以冒泡排序是稳定的排序算法。
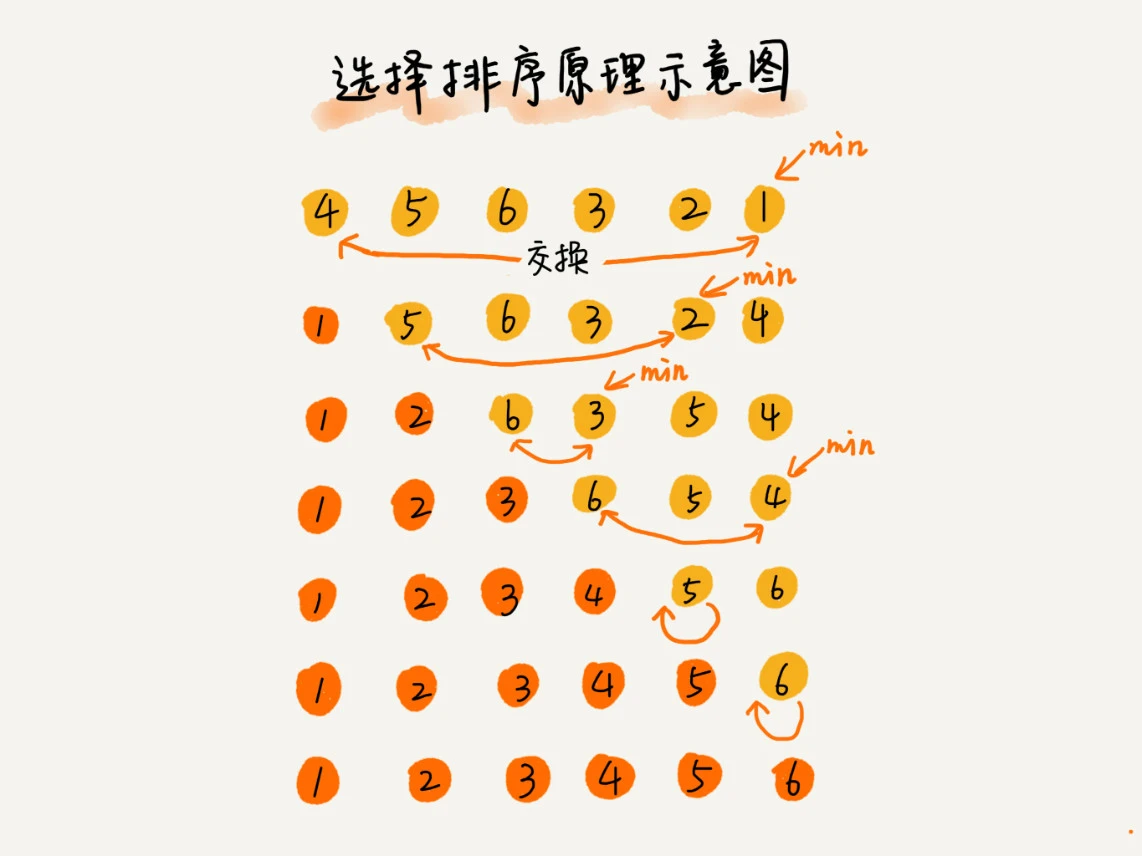
选择排序(Selection Sort)
选择排序将数组中的数据分为两个区间,已排序区间和未排序区间。每次会从未排序区间中找到最小的元素,将其放到已排序区间的末尾,共执行 n - 1 轮。
function selectionSort(arr) {
const n = arr.length;
let temp, minIndex;
for (let i = 0; i < n - 1; i++) {
minIndex = i;
for (let j = i + 1; j < n; j++) {
if (arr[j] < arr[minIndex]) {
// 寻找最小值
minIndex = j; // 暂存最小值的索引
}
}
temp = arr[i]; // 将最小值和第一个未排序的数交换
arr[i] = arr[minIndex];
arr[minIndex] = temp;
}
return arr;
}
选择排序空间复杂度为 O(1),是一种原地排序算法。选择排序的最好情况时间复杂度、最坏情况和平均情况时间复杂度都为 O(n2)。选择排序是一种不稳定的排序算法。选择排序每次都要找剩余未排序元素中的最小值,并和前面的元素交换位置,这样破坏了稳定性。
插入排序(Insertion Sort)
插入排序将数组中的数据分为两个区间,已排序区间和未排序区间。初始已排序区间只有一个元素,就是数组的第一个元素。插入算法的核心思想是取未排序区间中的元素,在已排序区间中找到合适的插入位置将其插入,并保证已排序区间数据一直有序。重复这个过程,直到未排序区间中元素为空,算法结束。 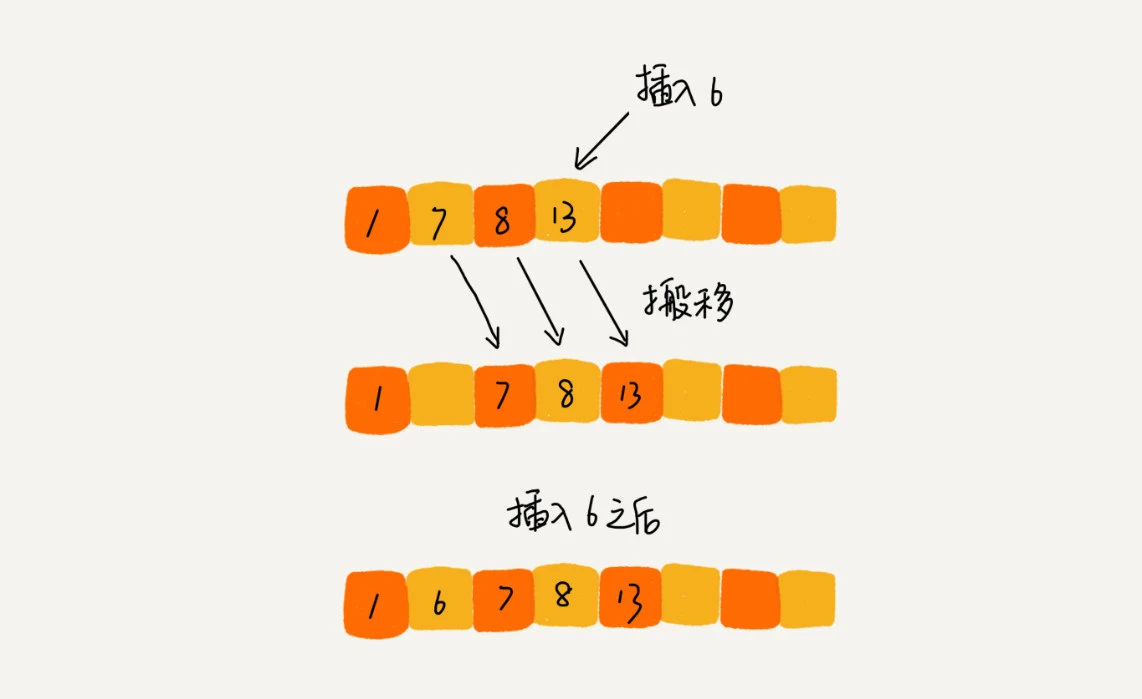
function insertionSort(arr) {
for (let i = 1; i < arr.length; i++) {
// 当前要处理的数
let temp = arr[i];
let j = i - 1;
while (j >= 0 && arr[j] > temp) {
// 如果前一个数大于后一个数,将前一个数往后移一位
arr[j + 1] = arr[j];
j--;
}
// 此时的j是要处理的数排序后应该在的位置
arr[j + 1] = temp;
}
return arr;
}
插入排序的平均时间复杂度是 O(n^2),冒泡的过程只涉及相邻数据的交换操作,只需要常量级的临时空间,所以它的空间复杂度为 O(1),是一个原地排序算法。相同大小的数据在排序前后不会改变顺序,所以冒泡排序是稳定的排序算法。
希尔排序(Shell Sort)
希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
- 插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率;
- 但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位;
希尔排序通过将比较的全部元素分为几个区域来提升插入排序的性能。这样可以让一个元素可以一次性地朝最终位置前进一大步。然后算法再取越来越小的步长进行排序,算法的最后一步就是普通的插入排序,但是到了这步,需排序的数据几乎是已排好的了。
function shellSort(arr) {
for (let gap = arr.length >> 1; gap > 0; gap >>= 1) {
for (let i = gap; i < arr.length; i++) {
let temp = arr[i],
j;
for (j = i - gap; j >= 0 && arr[j] > temp; j -= gap) {
arr[j + gap] = arr[j];
}
arr[j + gap] = temp;
}
}
return arr;
}
希尔排序的平均时间复杂度是 O(nlogn),空间复杂度为 O(1),希尔排序是非稳定排序算法。
归并排序(Merge Sort)
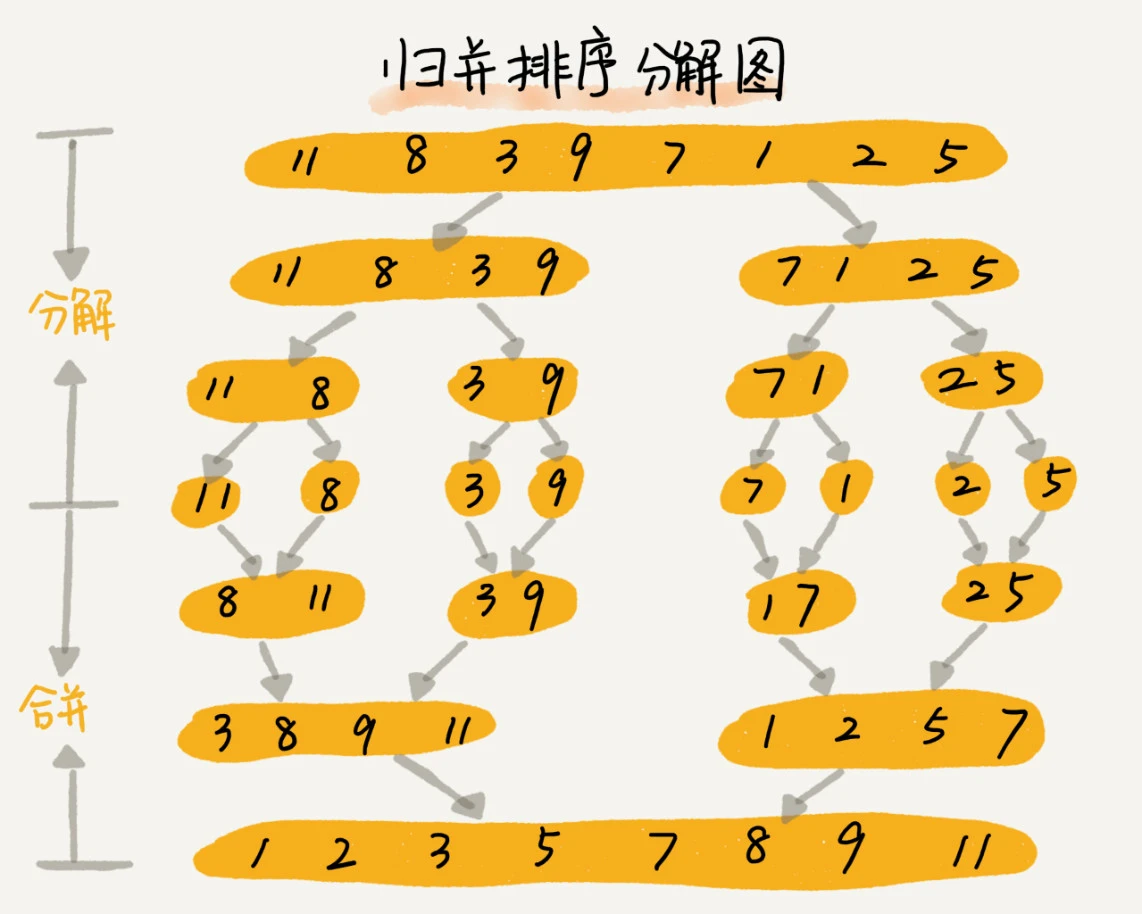
归并排序的核心思想是分治思想。分治,将一个大问题分解成小的子问题来解决。小的子问题解决了,大问题也就解决了。
如果要排序一个数组,先把数组从中间分成前后两部分,然后对前后两部分分别排序,再将排好序的两部分合并在一起,这样整个数组就都有序了。
分:把数组分成两半,递归子数组,进行分割操作,直到分成一个数
合:把两个字数组合并成一个有序数组,直到全部子数组合并完毕,合并前先准备一个空数组,存放合并之后的结果,然后不断取出两个子数组的第一个元素,比较他们的大小,小的先进入之前准备的空数组中,然后继续遍历其他元素,直到子数组中的元素都完成遍历
function mergeSort(arr) {
//采用自上而下的递归方法
var len = arr.length;
if (len < 2) {
return arr;
}
var middle = Math.floor(len / 2),
left = arr.slice(0, middle),
right = arr.slice(middle);
return merge(mergeSort(left), mergeSort(right));
}
function merge(left, right) {
var result = [];
while (left.length && right.length) {
if (left[0] <= right[0]) {
result.push(left.shift());
} else {
result.push(right.shift());
}
}
while (left.length) result.push(left.shift());
while (right.length) result.push(right.shift());
return result;
}
时间复杂度 O(nlogn),分的时间复杂度 O(logn),合并的过程的复杂度是 O(n)。
尽管每次合并操作都需要申请额外的内存空间,但在合并完成之后,临时开辟的内存空间就被释放掉了。在任意时刻,CPU 只会有一个函数在执行,也就只会有一个临时的内存空间在使用。临时内存空间最大也不会超过 n 个数据的大小,所以空间复杂度是 O(n)。
归并排序不是原地排序算法,归并排序是一个稳定的排序算法。
快速排序(Quick Sort)
快排利用的也是分治思想。
- 分区:从数组中选一个基准值,比基准值小的放在它的前面,比基准值大的放在它的后面
- 递归:对基准值前后的子数组进行第一步的递归操作
快排是一种原地、不稳定的排序算法。时间复杂度 O(nlogn),递归复杂度是 O(logn),分区复杂度 O(n);空间复杂度是 O(1)。
function quickSort(arr, left, right) {
var len = arr.length,
partitionIndex,
left = typeof left != 'number' ? 0 : left,
right = typeof right != 'number' ? len - 1 : right;
if (left < right) {
partitionIndex = partition(arr, left, right);
quickSort(arr, left, partitionIndex - 1);
quickSort(arr, partitionIndex + 1, right);
}
return arr;
}
//分区操作
function partition(arr, left, right) {
// 设定基准值位置 pivot
// 当然也可以选择最右边的元素为基准
// 也可以随机选择然后和最左或最右元素交换
var pivot = left,
index = pivot + 1;
for (var i = index; i <= right; i++) {
if (arr[i] < arr[pivot]) {
swap(arr, i, index);
index++;
}
}
swap(arr, pivot, index - 1);
return index - 1;
}
function swap(arr, i, j) {
var temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
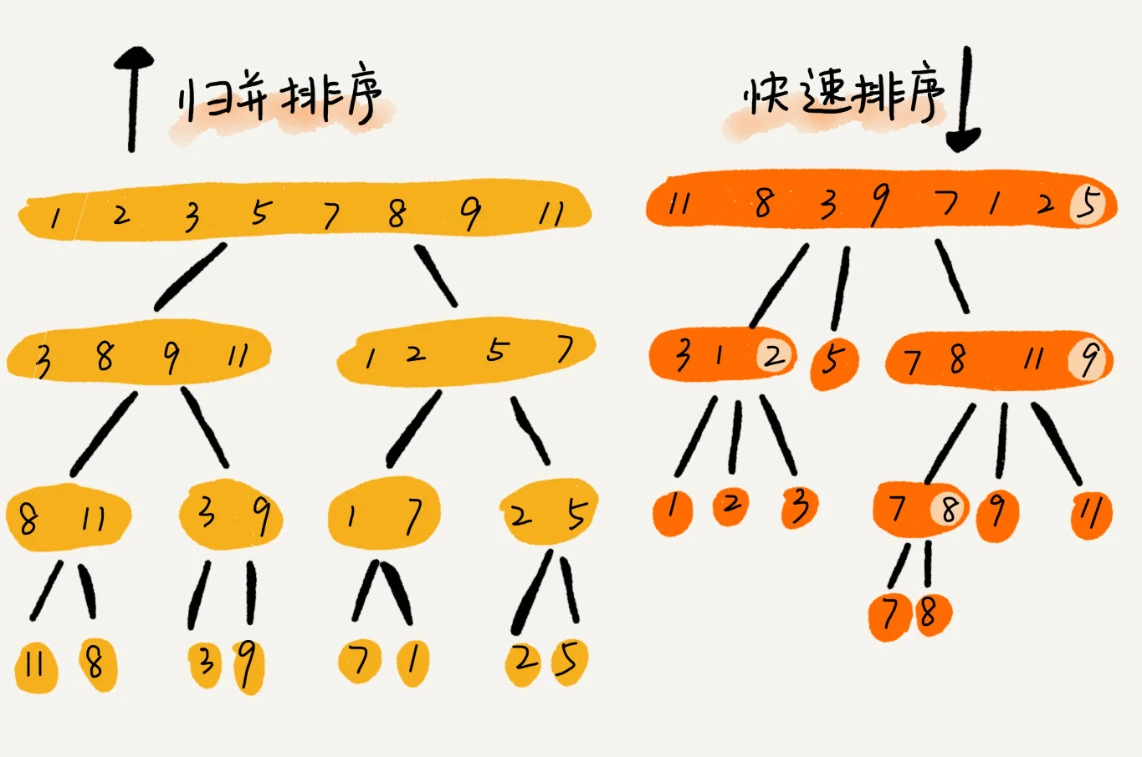
快排和归并用的都是分治思想,递推公式和递归代码也非常相似,它们的区别是:
- 归并排序的处理过程是由下到上的,先处理子问题,然后再合并。而快排正好相反,它的处理过程是由上到下的,先分区,然后再处理子问题。
- 归并排序虽然是稳定的、时间复杂度为 O(nlogn)的排序算法,但是它是非原地排序算法,它的合并函数无法在原地执行。快速排序通过设计巧妙的原地分区函数,可以实现原地排序,解决了归并排序占用太多内存的问题。
桶排序(Bucket sort)
桶排序,顾名思义,会用到“桶”,核心思想是将要排序的数据分到几个有序的桶里,每个桶里的数据再单独进行排序。桶内排完序之后,再把每个桶里的数据按照顺序依次取出,组成的序列就是有序的了。

桶排序的时间复杂度是 O(n)。如果要排序的数据有 n 个,我们把它们均匀地划分到 m 个桶内,每个桶里就有 k=n/m 个元素。每个桶内部使用快速排序,时间复杂度为 O(k _ logk)。m 个桶排序的时间复杂度就是 O(m _ k * logk),因为 k=n/m,所以整个桶排序的时间复杂度就是 O(n*log(n/m))。当桶的个数 m 接近数据个数 n 时,log(n/m)就是一个非常小的常量,这个时候桶排序的时间复杂度接近 O(n)。
桶排序对要排序数据的要求是非常苛刻的。要求数据在各个桶之间的分布是比较均匀的。如果数据经过桶的划分之后,有些桶里的数据非常多,有些非常少,很不平均,那桶内数据排序的时间复杂度就不是常量级了。在极端情况下,如果数据都被划分到一个桶里,那就退化为 O(nlogn)的排序算法了。
桶排序比较适合用在外部排序中。所谓的外部排序就是数据存储在外部磁盘中,数据量比较大,内存有限,无法将数据全部加载到内存中。
比如有 10GB 的订单数据,希望按订单金额(假设金额都是正整数)进行排序,但是内存有限,只有几百 MB,没办法一次性把 10GB 的数据都加载到内存中。
可以先扫描一遍文件,看订单金额所处的数据范围。假设经过扫描之后得到,订单金额最小是 1 元,最大是 10 万元。将所有订单根据金额划分到 100 个桶里,第一个桶存储金额在 1 元到 1000 元之内的订单,第二桶存储金额在 1001 元到 2000 元之内的订单,以此类推。每一个桶对应一个文件,并且按照金额范围的大小顺序编号命名(00,01,02…99)。
不过,订单按照金额在 1 元到 10 万元之间并不一定是均匀分布的 ,所以 10GB 订单数据无法均匀地被划分到 100 个文件中的。有可能某个金额区间的数据特别多,划分之后对应的文件就会很大,没法一次性读入内存。这时可以继续划分,比如,订单金额在 1 元到 1000 元之间的比较多,就将这个区间继续划分为 10 个小区间,1 元到 100 元,101 元到 200 元,201 元到 300 元…901 元到 1000 元。如果划分之后,101 元到 200 元之间的订单还是太多,无法一次性读入内存,那就继续再划分,直到所有的文件都能读入内存为止。
- 平均时间复杂度:O(n + k),其中 n 是待排序数组的大小,k 是整数范围;
- 最坏时间复杂度:O(n^2);
- 最佳时间复杂度:O(n + k);
- 空间复杂度:O(n + k),需要额外的计数数组和结果数组;
- 稳定性:桶排序是一种稳定的排序算法,不改变相同元素的相对顺序;
计数排序(Counting sort)
计数排序是一种非比较排序算法,其核心思想是通过计数每个元素的出现次数来进行排序,适用于整数或有限范围内的非负整数排序。这个算法的特点是速度快且稳定,适用于某些特定场景。
计数排序其实是桶排序的一种特殊情况。当要排序的 n 个数据,所处的范围并不大的时候,比如最大值是 k,我们就可以把数据划分成 k 个桶。每个桶内的数据值都是相同的,省掉了桶内排序的时间。
比如高考查分数系统,查分数的时候,系统会显示成绩以及所在省的排名。如果所在省有 50 万考生,如何通过成绩快速排序得出名次。
考生的满分是 900 分,最小是 0 分,这个数据的范围很小,可以分成 901 个桶,对应分数从 0 分到 900 分。根据考生的成绩,将这 50 万考生划分到这 901 个桶里。桶内的数据都是分数相同的考生,所以并不需要再进行排序。只需要依次扫描每个桶,将桶内的考生依次输出到一个数组中,就实现了 50 万考生的排序。因为只涉及扫描遍历操作,所以时间复杂度是 O(k)。
- 平均时间复杂度:O(n + k),其中 n 是待排序数组的大小,k 是整数范围;
- 最坏时间复杂度:O(n + k);
- 最佳时间复杂度:O(n + k);
- 空间复杂度:O(k);
- 稳定性:计数排序是一种稳定的排序算法,不改变相同元素的相对顺序;
基数排序(Radix sort)
基数排序是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排序也不是只能使用于整数。
它是这样实现的:将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后,数列就变成一个有序序列。
- 平均时间复杂度:
O(n * k),其中 n 是待排序数组的大小,k 是整数范围; - 最坏时间复杂度:
O(n * k); - 最佳时间复杂度:
O(n * k); - 空间复杂度:O(n + k),需要额外的计数数组和结果数组;
- 稳定性:基数排序是一种稳定的排序算法,不改变相同元素的相对顺序;
上述三种排序算法都利用了桶的概念,但对桶的使用方法上有明显差异:
- 桶排序:每个桶存储一定范围的数值;
- 计数排序:每个桶只存储单一键值;
- 基数排序:根据键值的每位数字来分配桶;
相关题目
数组排序
- 冒泡排序
| 题号 | 标题 | 题解 | 标签 | 难度 | 力扣 |
|---|---|---|---|---|---|
| 剑指 Offer 45 | 把数组排成最小的数 | [✓] | 贪心 字符串 排序 | 🟠 | 🀄️ |
| 283 | 移动零 | [✓] | 数组 双指针 | 🟢 | 🀄️ 🔗 |
- 选择排序
| 题号 | 标题 | 题解 | 标签 | 难度 | 力扣 |
|---|---|---|---|---|---|
| 215 | 数组中的第K个最大元素 | [✓] | 数组 分治 快速选择 2+ | 🟠 | 🀄️ 🔗 |
- 插入排序
| 题号 | 标题 | 题解 | 标签 | 难度 | 力扣 |
|---|---|---|---|---|---|
| 75 | 颜色分类 | [✓] | 数组 双指针 排序 | 🟠 | 🀄️ 🔗 |
- 希尔排序
| 题号 | 标题 | 题解 | 标签 | 难度 | 力扣 |
|---|---|---|---|---|---|
| 912 | 排序数组 | 数组 分治 桶排序 5+ | 🟠 | 🀄️ 🔗 | |
| 506 | 相对名次 | [✓] | 数组 排序 堆(优先队列) | 🟢 | 🀄️ 🔗 |
- 归并排序
| 题号 | 标题 | 题解 | 标签 | 难度 | 力扣 |
|---|---|---|---|---|---|
| 912 | 排序数组 | 数组 分治 桶排序 5+ | 🟠 | 🀄️ 🔗 | |
| 88 | 合并两个有序数组 | [✓] | 数组 双指针 排序 | 🟢 | 🀄️ 🔗 |
| 剑指 Offer 51 | 数组中的逆序对 | [✓] | 树状数组 线段树 数组 4+ | 🔴 | 🀄️ |
| 315 | 计算右侧小于当前元素的个数 | 树状数组 线段树 数组 4+ | 🔴 | 🀄️ 🔗 |
- 快速排序
| 题号 | 标题 | 题解 | 标签 | 难度 | 力扣 |
|---|---|---|---|---|---|
| 912 | 排序数组 | 数组 分治 桶排序 5+ | 🟠 | 🀄️ 🔗 | |
| 169 | 多数元素 | [✓] | 数组 哈希表 分治 2+ | 🟢 | 🀄️ 🔗 |
- 堆排序
| 题号 | 标题 | 题解 | 标签 | 难度 | 力扣 |
|---|---|---|---|---|---|
| 912 | 排序数组 | 数组 分治 桶排序 5+ | 🟠 | 🀄️ 🔗 | |
| 215 | 数组中的第K个最大元素 | [✓] | 数组 分治 快速选择 2+ | 🟠 | 🀄️ 🔗 |
| 剑指 Offer 40 | 最小的k个数 | [✓] | 数组 分治 快速选择 2+ | 🟢 | 🀄️ |
- 计数排序
| 题号 | 标题 | 题解 | 标签 | 难度 | 力扣 |
|---|---|---|---|---|---|
| 912 | 排序数组 | 数组 分治 桶排序 5+ | 🟠 | 🀄️ 🔗 | |
| 1122 | 数组的相对排序 | [✓] | 数组 哈希表 计数排序 1+ | 🟢 | 🀄️ 🔗 |
- 桶排序
| 题号 | 标题 | 题解 | 标签 | 难度 | 力扣 |
|---|---|---|---|---|---|
| 912 | 排序数组 | 数组 分治 桶排序 5+ | 🟠 | 🀄️ 🔗 | |
| 220 | 存在重复元素 III | 数组 桶排序 有序集合 2+ | 🔴 | 🀄️ 🔗 | |
| 164 | 最大间距 | [✓] | 数组 桶排序 基数排序 1+ | 🟠 | 🀄️ 🔗 |
- 基数排序
| 题号 | 标题 | 题解 | 标签 | 难度 | 力扣 |
|---|---|---|---|---|---|
| 164 | 最大间距 | [✓] | 数组 桶排序 基数排序 1+ | 🟠 | 🀄️ 🔗 |
| 561 | 数组拆分 | [✓] | 贪心 数组 计数排序 1+ | 🟢 | 🀄️ 🔗 |
- 其他排序
| 题号 | 标题 | 题解 | 标签 | 难度 | 力扣 |
|---|---|---|---|---|---|
| 217 | 存在重复元素 | [✓] | 数组 哈希表 排序 | 🟢 | 🀄️ 🔗 |
| 136 | 只出现一次的数字 | [✓] | 位运算 数组 | 🟢 | 🀄️ 🔗 |
| 56 | 合并区间 | [✓] | 数组 排序 | 🟠 | 🀄️ 🔗 |
| 179 | 最大数 | [✓] | 贪心 数组 字符串 1+ | 🟠 | 🀄️ 🔗 |
| 384 | 打乱数组 | [✓] | 数组 数学 随机化 | 🟠 | 🀄️ 🔗 |
| 剑指 Offer 45 | 把数组排成最小的数 | [✓] | 贪心 字符串 排序 | 🟠 | 🀄️ |