2.2 链表
2.2 链表
链表的定义
定义
链表(Linked list) 通过“指针”将一组零散的内存块串联起来使用,它并不需要一块连续的内存空间。
最常见的链表结构有:单链表、循环链表和双向链表。
1. 单链表
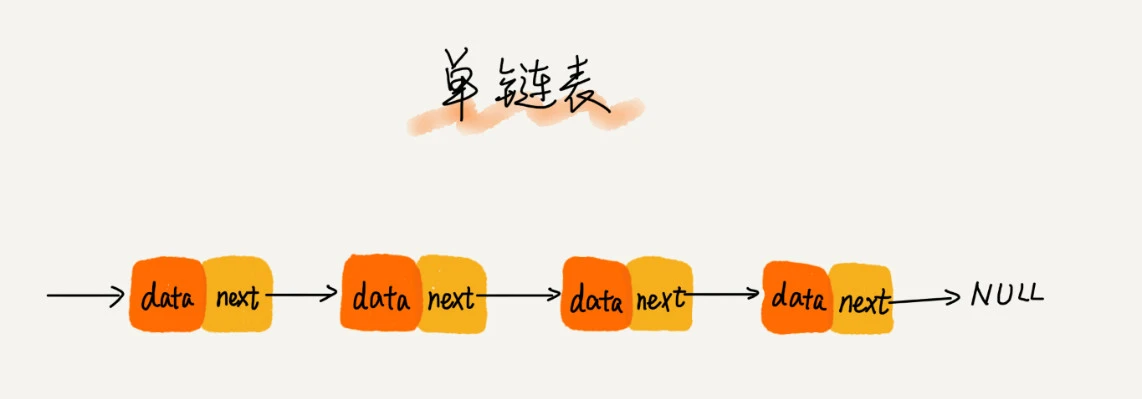
我们把内存块称为链表的 “节点”。为了将所有的节点串起来,每个链表的节点除了存储数据之外,还需要记录链上的下一个节点的地址。这个记录下个节点地址的指针叫作后继指针next。
第一个节点叫作头节点,把最后一个节点叫作尾节点。其中,头节点用来记录链表的基地址。有了它就可以遍历得到整条链表。而尾节点特殊的地方是:指针不是指向下一个节点,而是指向一个空地址 NULL,表示这是链表上最后一个节点。
先简单介绍一下链表结构的优缺点:
优点:存储空间不必事先分配,在需要存储空间的时候可以临时申请,不会造成空间的浪费;链表最大的优点在于可以灵活的添加和删除元素,插入、移动、删除元素的时间效率远比数组高。
缺点:不仅数据元素本身的数据信息要占用存储空间,指针也需要占用存储空间,链表结构比数组结构的空间开销大。
2. 循环链表
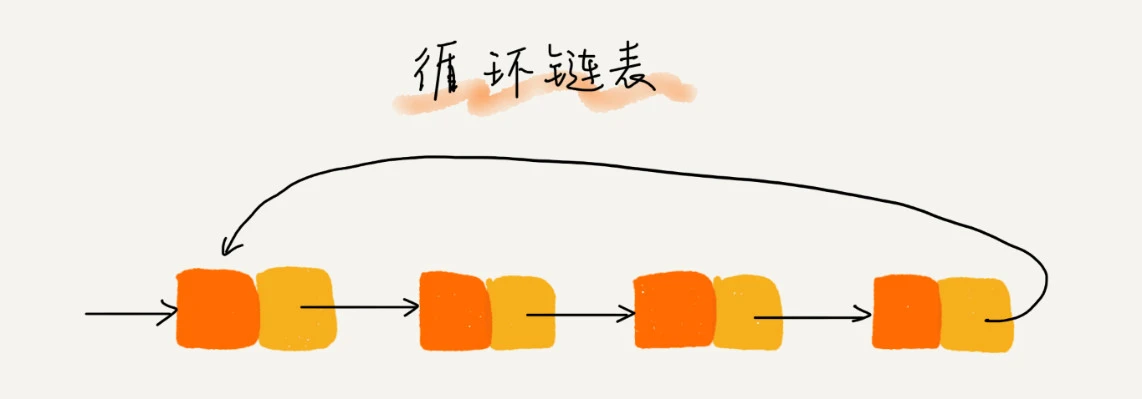
循环链表是一种特殊的单链表。它跟单链表唯一的区别就在尾节点。单链表的尾节点指针指向空地址,表示这就是最后的节点了。而循环链表的尾节点指针是指向链表的头节点。像一个环一样首尾相连,所以叫作“循环”链表。
和单链表相比,循环链表的优点是从链尾到链头比较方便。当要处理的数据具有环型结构特点时,就特别适合采用循环链表。比如著名的约瑟夫问题,尽管用单链表也可以实现,但是用循环链表实现的话,代码就会简洁很多。
3. 双向链表

单向链表只有一个方向,节点只有一个后继指针 next 指向后面的节点。而双向链表支持两个方向,每个节点不止有一个后继指针 next 指向后面的节点,还有一个前驱指针 prev 指向前面的节点。
双向链表需要额外的两个空间来存储后继节点和前驱节点的地址。所以存储同样多的数据,双向链表要比单链表占用更多的内存空间。虽然两个指针比较浪费存储空间,但可以支持双向遍历,支持 O(1) 时间复杂度的情况下找到前驱节点,这也使双向链表在某些情况下的插入、删除等操作都要比单链表简单、高效。
除了插入、删除操作有优势之外,对于一个有序链表,双向链表的按值查询的效率也要比单链表高一些。因为可以记录上次查找的位置 p,每次查询时,根据要查找的值与 p 的大小关系,决定是往前还是往后查找,所以平均只需要查找一半的数据。
这就是用空间换时间的设计思想。当内存空间充足的时候,如果我们更加追求代码的执行速度,我们就可以选择空间复杂度相对较高、但时间复杂度相对很低的算法或者数据结构。相反,如果内存比较紧缺,比如代码跑在手机或者单片机上,这个时候,就要反过来用时间换空间的设计思路。
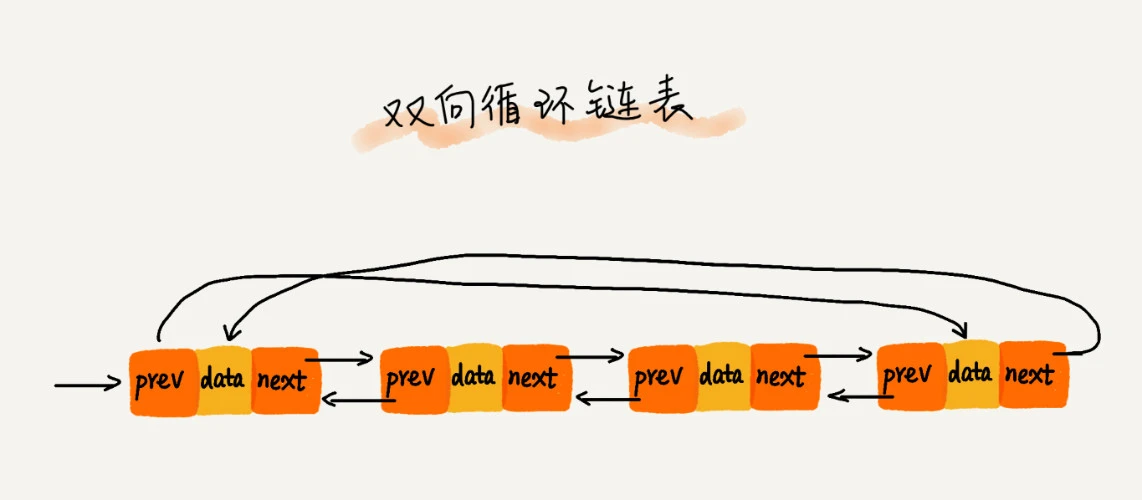
4. 双向循环链表
如果把循环链表和双向链表这两种链表整合在一起,就是一个新的版本:双向循环链表。
链表的操作
数据结构的操作一般涉及到增、删、改、查 4 种情况,链表的操作也基本上是这 4 种情况。
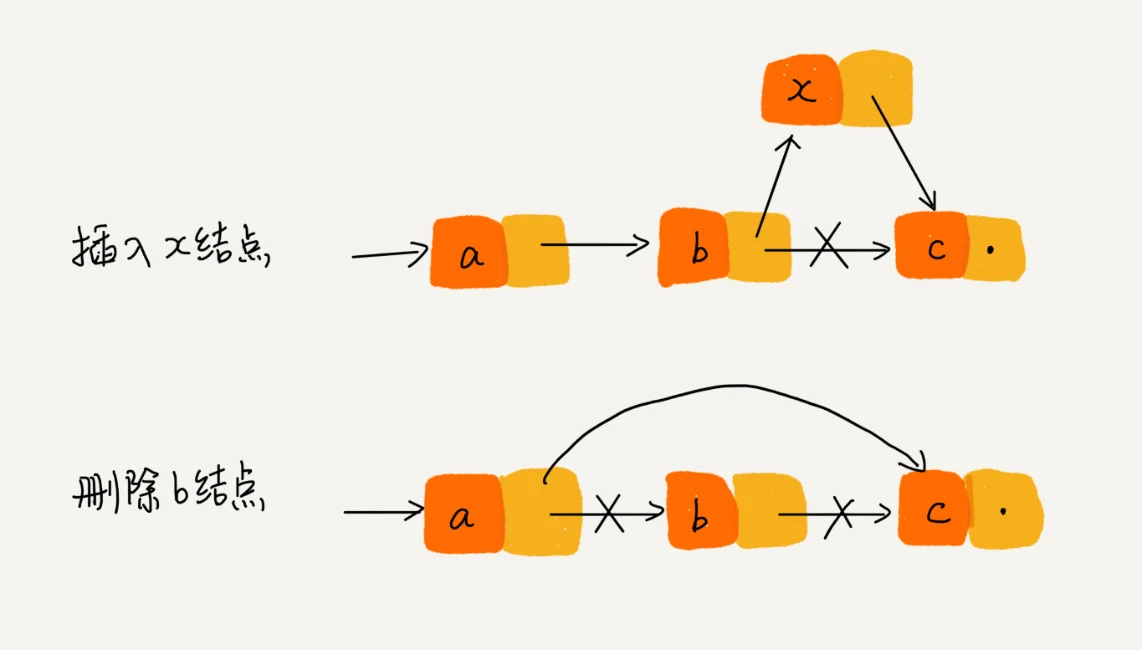
1. 插入节点
向链表中插入一个节点的效率很高,需要修改它前面的节点(前驱),使其指向新加入的节点,而将新节点指向原来前驱节点指向的节点即可。
比如单链表的插入操作,要在节点 p 后面插入一个新的节点,只需要下面两行代码:
new_node.next = p.next;
p.next = new_node;
但是如果要向一个空链表中插入第一个节点,需要进行特殊处理:
// 其中 head 表示链表的头节点
if (head == null) {
head = new_node;
}
2. 删除节点
同样,从链表中删除一个节点,也很简单。只需将待删节点的前驱节点指向待删节点的,同时将待删节点指向 null,那么节点就删除成功了。
比如单链表节点删除操作,如果要删除节点 p 的后继节点,只需要一行代码:p.next = p.next.next;
但是,如果要删除链表中的最后一个节点,则需要特殊处理:
if (head.next == null) {
head = null;
}
在进行数组的插入、删除操作时,为了保持内存数据的连续性,需要做大量的数据搬移,所以时间复杂度是 O(n)。
而在链表中插入或者删除一个数据,我们并不需要为了保持内存的连续性而搬移节点,因为链表的存储空间本身就不是连续的。所以,在链表中插入和删除一个数据是非常快速的,我们只需要考虑相邻节点的指针改变,所以对应的时间复杂度是 O(1)。
3. 查找节点
链表要想随机访问第 k 个元素,没有数组那么高效。
因为链表中的数据并非连续存储的,无法像数组那样,根据首地址和下标,通过寻址公式直接计算出对应的内存地址,而是需要根据指针一个节点一个节点地依次遍历,直到找到相应的节点。
所以,链表随机访问的性能没有数组好,需要 O(n) 的时间复杂度。
4. 修改节点
修改链表中某个节点的值,只需修改该节点的data值即可。
5. 增加节点
向链表尾部添加节点,需要判断以下链表是否为空,若是空链表,直接将链表的 head 指向新节点,否则需要遍历链表直至找到链表尾节点,再将尾节点的 head 指向新节点。
链表的实现
单向链表
单向链表的实现包含两个类,一个是 Node 类,用来表示节点;另一个是 SingleLinkedList 类,提供了对链表进行操作的方法。
Node类包含两个属性:data保存节点上的数据,next指向后一个节点;SingleLinkedList类包含两个属性:head保存该链表的头节点,length保存链表包含的节点个数,还提供了对链表进行操作的方法:append(data)向链表尾部添加一个新的项;insert(position, data)向链表的特定位置插入一个新的项;getData(position)获取对应位置的节点;indexOf(data)返回节点在链表中的索引,如果链表中没有该节点就返回-1;update(position, data)修改某个位置的节点;removeAt(position)从链表的特定位置移除一项;remove(data)从链表中移除一项;isEmpty()判断链表是否为空,返回Boolean值;count()返回链表包含的节点个数,与数组的length属性类似;toString()将链表中节点以字符串形式返回;
👉 查看代码 👈
// 节点类
class Node {
constructor(data) {
this.data = data;
this.next = null;
}
}
// 单项链表类
class SingleLinkedList {
constructor() {
this.head = null;
this.length = 0;
}
// 在链尾添加节点
append(data) {
let node = new Node(data);
if (this.head === null) {
this.head = node;
} else {
let current = this.head;
while (current.next) {
current = current.next;
}
current.next = node;
}
this.length++;
}
// 在指定位置(position)插入节点
// position = 0 表示新插入后是第一个节点
// position = 1 表示新插入后是第二个节点,以此类推
insert(position, data) {
if (position < 0 || position > this.length) return false;
let node = new Node(data);
let prev = new Node(0);
prev.next = this.head;
let index = 0;
while (index < position) {
prev = prev.next;
index++;
}
let temp = prev.next;
prev.next = node;
node.next = temp;
if (position === 0) {
this.head = node;
}
this.length++;
return node;
}
// 获取指定位置(position)的元素
getData(position) {
if (position < 0 || position >= this.length) return null;
let prev = this.head;
let index = 0;
while (index < position) {
prev = prev.next;
index++;
}
return prev.data;
}
// 返回指定 data 的 index,如果没有则返回 -1
indexOf(data) {
let prev = this.head;
let index = 0;
while (prev) {
if (prev.data === data) return index;
prev = prev.next;
index++;
}
return -1;
}
// 修改指定位置(position)的节点
update(position, data) {
if (position < 0 || position >= this.length) return null;
let prev = this.head;
let index = 0;
while (index < position) {
prev = prev.next;
index++;
}
prev.data = data;
}
// 删除指定位置(position)的节点
removeAt(position) {
if (position < 0 || position >= this.length) return false;
let prev = new Node(0);
prev.next = this.head;
let index = 0;
while (index < position) {
prev = prev.next;
index++;
}
let node = prev.next;
prev.next = node.next;
if (position === 0) {
this.head = node.next;
}
this.length--;
return node;
}
// 删除节点
remove(data) {
return this.removeAt(this.indexOf(data));
}
// 判断链表是否为空,返回 Boolean 值
isEmpty() {
return this.length === 0;
}
// 返回链表包含的节点个数
count() {
return this.length;
}
// 将链表中节点以字符串形式返回
toString() {
let prev = this.head;
let res = [];
while (prev) {
res.push(prev.data);
prev = prev.next;
}
return res.join(',');
}
}
代码测试:
const linkedList = new SingleLinkedList();
linkedList.append('A');
linkedList.append('B');
linkedList.append('C');
console.log(linkedList);
// output:
// SingleLinkedList {
// head: Node {data: "A", next:
// Node {data: "B", next:
// Node {data: "C", next: null}}},
// length: 3}
console.log(linkedList.toString()); // output: A,B,C
linkedList.insert(0, '123');
linkedList.insert(2, '456');
console.log(linkedList.toString()); // output: 123,A,456,B,C
console.log(linkedList.getData(0)); // output: 123
console.log(linkedList.getData(1)); // output: A
console.log(linkedList.indexOf('A')); // output: 1
console.log(linkedList.indexOf('ABC')); // output: -1
linkedList.update(0, '12345');
console.log(linkedList.toString()); // output: 12345,A,456,B,C
linkedList.update(1, '54321');
console.log(linkedList.toString()); // output: 12345,54321,456,B,C
linkedList.removeAt(3);
console.log(linkedList.toString()); // output: 12345,54321,456,C
linkedList.remove('12345');
console.log(linkedList.toString()); // output: 54321,456,C
console.log(linkedList.isEmpty()); // output: false
console.log(linkedList.count()); // output: 3
双向链表
双向链表相连的过程是双向的,实现原理包含两个类:
一个是 DoublyNode 类,用来表示节点,它除了有指向后一个节点的 next 指针,还有指向前一个节点的 prev 指针,第一个节点的 prev 指向 null,最后一个节点的 next 指向 null;
另一个是 DoublyLinkedList 类,提供了对双向链表进行操作的方法,它不仅有 head 指针指向第一个节点,而且有 tail 指针指向最后一个节点。
DoublyNode类包含三个属性:data储存数据,prev指向前一个节点,next指向后一个节点;DoublyLinkedList类包含三个属性:head保存该链表的头节点,tail保存该链表的尾节点,length保存链表包含的节点个数,还提供了对双向链表进行操作的方法:append(data)向链表尾部添加一个新的项;insert(position, data)向链表的特定位置插入一个新的项;getData(position)获取对应位置的节点;indexOf(data)返回节点在链表中的索引,如果链表中没有该节点就返回-1;update(position, data)修改某个位置的节点;removeAt(position)从链表的特定位置移除一项;remove(data)从链表中移除一项;isEmpty()判断链表是否为空,返回Boolean值;count()返回链表包含的节点个数,与数组的length属性类似;toString()将链表中节点以字符串形式返回;backwordString()反向遍历节点,以字符串形式返回;
👉 查看代码 👈
// 双向链表的节点类(继承单向链表的节点类)
class DoublyNode extends Node {
constructor(data) {
super(data);
this.prev = null;
}
}
// 双向链表类(继承单向链表类)
class DoublyLinkedList extends SingleLinkedList {
constructor() {
super();
this.tail = null;
}
// 在链尾添加节点,重写 append()
append(data) {
let node = new DoublyNode(data);
if (this.head === null) {
this.head = node;
this.tail = node;
} else {
// 直接通过 tail 指针在链尾添加节点
this.tail.next = node;
node.prev = this.tail;
this.tail = node;
}
this.length++;
}
// 在指定位置(position)插入节点,重写 insert()
insert(position, data) {
if (position < 0 || position > this.length) return false;
let node = new DoublyNode(data);
let cur = new DoublyNode(null);
cur.next = this.head;
let index = 0;
while (index < position) {
cur = cur.next;
index++;
}
let temp = cur.next;
cur.next = node;
node.next = temp;
node.prev = cur;
temp.prev = node;
if (position === 0) {
this.head = node;
this.head.prev = null;
}
if (position === this.length) {
this.tail = node;
}
this.length++;
return node;
}
// 删除指定位置(position)的节点,重写 removeAt()
removeAt(position) {
if (position < 0 || position >= this.length) return false;
let cur = new DoublyNode(null);
cur.next = this.head;
let index = 0;
while (index < position) {
cur = cur.next;
index++;
}
let node = cur.next;
cur.next = node.next;
if (node.next) {
node.next.prev = cur;
}
if (position === 0) {
this.head = node.next;
this.head.prev = null;
}
if (position === this.length - 1) {
this.tail = this.tail.prev;
}
this.length--;
return node;
}
// 反向遍历节点,以字符串形式返回
backwordString() {
let cur = this.tail;
let res = [];
while (cur) {
res.push(cur.data);
cur = cur.prev;
}
return res.join(',');
}
// 其他方法都继承 SingleLinkedList 类的
}
代码测试:
const linkedList = new DoublyLinkedList();
linkedList.append('A');
linkedList.append('B');
linkedList.append('C');
console.log(linkedList.toString()); // output: A,B,C
console.log(linkedList.backwordString()); // output: C,B,A
linkedList.insert(0, '123');
linkedList.insert(2, '456');
console.log(linkedList.toString()); // output: 123,A,456,B,C
console.log(linkedList.backwordString()); // output: C,B,456,A,123
console.log(linkedList.getData(0)); // output: 123
console.log(linkedList.getData(1)); // output: A
console.log(linkedList.indexOf('A')); // output: 1
console.log(linkedList.indexOf('ABC')); // output: -1
linkedList.update(0, '12345');
console.log(linkedList.toString()); // output: 12345,A,456,B,C
console.log(linkedList.backwordString()); // output: C,B,456,A,12345
linkedList.update(1, '54321');
console.log(linkedList.toString()); // output: 12345,54321,456,B,C
console.log(linkedList.backwordString()); // output: C,B,456,54321,12345
linkedList.removeAt(3);
console.log(linkedList.toString()); // output: 12345,54321,456,C
console.log(linkedList.backwordString()); // output: C,456,54321,12345
linkedList.remove('12345');
console.log(linkedList.toString()); // output: 54321,456,C
console.log(linkedList.backwordString()); // output: C,456,54321
console.log(linkedList.isEmpty()); // output: false
console.log(linkedList.count()); // output: 3
链表 VS 数组
相比数组,链表是一种稍微复杂一点的数据结构。这两个非常基础、非常常用的数据结构,常常被放到一块儿比较,那它们有什么区别呢?
先从底层的存储结构上来看:

从图中可以看到,数组需要一块连续的内存空间来存储,对内存的要求比较高。如果我们申请一个 100MB 大小的数组,当内存中没有连续的、足够大的存储空间时,即便内存的剩余总可用空间大于 100MB,仍然会申请失败。
而链表恰恰相反,它并不需要一块连续的内存空间,它通过“指针”将一组零散的内存块串联起来使用,所以如果我们申请的是 100MB 大小的链表,则不会有问题。
正是因为内存存储的区别,数组和链表在插入、删除、随机访问操作时的时间复杂度正好相反:
| 时间复杂度 | 链表 | 数组 |
|---|---|---|
| 插入 | O(1) | O(n) |
| 删除 | O(1) | O(n) |
| 随机访问 | O(n) | O(1) |
不过数组和链表的性能对比,并不能局限于时间复杂度。在实际的软件开发中,不能仅仅利用复杂度分析就决定使用哪个数据结构来存储数据。
数组简单易用,在实现上使用的是连续的内存空间,可以借助 CPU 的缓存机制,预读数组中的数据,所以访问效率更高。而链表在内存中并不是连续存储,所以对 CPU 缓存不友好,没办法有效预读。
数组的缺点是大小固定,一经声明就要占用整块连续内存空间。如果声明的数组过大,系统可能没有足够的连续内存空间分配给它,导致“内存不足(out of memory)”。如果声明的数组过小,则可能出现不够用的情况。这时只能再申请一个更大的内存空间,把原数组拷贝进去,非常费时。链表本身没有大小的限制,天然地支持动态扩容,这也是它与数组最大的区别。
除此之外,因为链表中的每个节点都需要消耗额外的存储空间去存储一份指向下一个节点的指针,所以内存消耗会翻倍。而且,对链表进行频繁的插入、删除操作,还会导致频繁的内存申请和释放,容易造成内存碎片。如果代码对内存的使用非常苛刻,那数组就更合适。
链表的应用
下面列举了 6 个常见的链表操作和应用,分别是:
- 反转单链表
- 检测链表中是否有环
- 合并两个有序链表
- 删除链表倒数第 n 个节点
- 求链表的中间节点
- LRU 缓存淘汰算法
只要把这几个操作都写熟练,多写多练,之后就再也不会害怕写链表代码。
1. 反转单链表
📌 206. 反转链表 - LeetCode
💻 题目大意
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
示例:

输入:head = [1,2,3,4,5]
输出:[5,4,3,2,1]

输入:head = [1,2]
输出:[2,1]
输入:head = []
输出:[]
说明:
- 链表中节点的数目范围是
[0, 5000] -5000 <= Node.val <= 5000
💡 解题思路
有两种思路,一是循环、二是递归。
💎 代码
👉 查看代码 👈
/**
* @param {ListNode} head
* @return {ListNode}
*/
// 循环实现
var reverseList = function (head) {
let prev = null;
let cur = head;
while (cur !== null) {
let next = cur.next;
cur.next = prev;
prev = cur;
cur = next;
}
return prev;
};
// 递归实现
var reverseList = function (head) {
if (head === null || head.next === null) {
return head;
}
const last = reverseList(head.next);
head.next.next = head;
head.next = null;
return last;
};
#### 📌 [206. 反转链表 - LeetCode](https://wangfuyou.com/leetcode-js/problem/0206.html)
#### 💻 **题目大意**
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
**示例**:

> 输入:head = [1,2,3,4,5]
>
> 输出:[5,4,3,2,1]

> 输入:head = [1,2]
>
> 输出:[2,1]
> 输入:head = []
>
> 输出:[]
**说明**:
- 链表中节点的数目范围是 `[0, 5000]`
- `-5000 <= Node.val <= 5000`
#### 💡 **解题思路**
有两种思路,一是循环、二是递归。
#### 💎 **代码**
<details>
<summary>👉 查看代码 👈</summary>
```javascript
/**
* @param {ListNode} head
* @return {ListNode}
*/
// 循环实现
var reverseList = function (head) {
let prev = null;
let cur = head;
while (cur !== null) {
let next = cur.next;
cur.next = prev;
prev = cur;
cur = next;
}
return prev;
};
// 递归实现
var reverseList = function (head) {
if (head === null || head.next === null) {
return head;
}
const last = reverseList(head.next);
head.next.next = head;
head.next = null;
return last;
};
```
</details>
2. 检测链表中是否有环
📌 141. 环形链表 - LeetCode
💻 题目大意
给你一个链表的头节点 head ,判断链表中是否有环。如果链表中存在环 ,则返回 true 。 否则,返回 false 。
示例:

输入:head = [3,2,0,-4], pos = 1
输出:true
解释:链表中有一个环,其尾部连接到第二个节点。

输入:head = [1,2], pos = 0
输出:true
解释:链表中有一个环,其尾部连接到第一个节点。

输入:head = [1], pos = -1
输出:false
解释:链表中没有环。
说明:
- 链表中节点的数目范围是
[0, 10^4] -10^5 <= Node.val <= 10^5pos为-1或者链表中的一个 有效索引 。
💡 解题思路
- 思路一:哈希表
- 最简单的思路是遍历所有节点,每次遍历节点之前,使用哈希表判断该节点是否被访问过;
- 如果访问过就说明存在环;
- 如果没访问过则将该节点添加到哈希表中,继续遍历判断;
- 思路二:快慢指针
- 两个指针从同一位置同时出发,一快一慢,如果有环,那么快的一方总能追上慢的一方;
- 慢指针每次前进一步,快指针每次前进 n 步(n >= 2);
- 如果两个指针在链表头节点以外的某一节点相遇了,那么说明链表有环;
- 否则,如果(快指针)到达了某个没有后继指针的节点时,那么说明没环;
💎 代码
👉 查看代码 👈
/**
* @param {ListNode} head
* @return {boolean}
*/
var hasCycle = function (head) {
let slow = head;
let fast = head;
while (fast && fast.next) {
slow = slow.next;
fast = fast.next.next;
if (fast == slow) return true;
}
return false;
};
#### 📌 [141. 环形链表 - LeetCode](https://wangfuyou.com/leetcode-js/problem/0141.html)
#### 💻 **题目大意**
给你一个链表的头节点 head ,判断链表中是否有环。如果链表中存在环 ,则返回 `true` 。 否则,返回 `false` 。
**示例**:

> 输入:head = [3,2,0,-4], pos = 1
>
> 输出:true
>
> 解释:链表中有一个环,其尾部连接到第二个节点。

> 输入:head = [1,2], pos = 0
>
> 输出:true
>
> 解释:链表中有一个环,其尾部连接到第一个节点。

> 输入:head = [1], pos = -1
>
> 输出:false
>
> 解释:链表中没有环。
**说明**:
- 链表中节点的数目范围是 `[0, 10^4]`
- `-10^5 <= Node.val <= 10^5`
- `pos` 为 `-1` 或者链表中的一个 有效索引 。
#### 💡 **解题思路**
- 思路一:哈希表
- 最简单的思路是遍历所有节点,每次遍历节点之前,使用哈希表判断该节点是否被访问过;
- 如果访问过就说明存在环;
- 如果没访问过则将该节点添加到哈希表中,继续遍历判断;
- 思路二:快慢指针
- 两个指针从同一位置同时出发,一快一慢,如果有环,那么快的一方总能追上慢的一方;
- 慢指针每次前进一步,快指针每次前进 n 步(n >= 2);
- 如果两个指针在链表头节点以外的某一节点相遇了,那么说明链表有环;
- 否则,如果(快指针)到达了某个没有后继指针的节点时,那么说明没环;
#### 💎 **代码**
<details>
<summary>👉 查看代码 👈</summary>
```javascript
/**
* @param {ListNode} head
* @return {boolean}
*/
var hasCycle = function (head) {
let slow = head;
let fast = head;
while (fast && fast.next) {
slow = slow.next;
fast = fast.next.next;
if (fast == slow) return true;
}
return false;
};
```
</details>
3. 合并两个有序链表
📌 21. 合并两个有序链表 - LeetCode
💻 题目大意
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例:

输入:l1 = [1,2,4], l2 = [1,3,4]
输出:[1,1,2,3,4,4]
输入:l1 = [], l2 = []
输出:[]
输入:l1 = [], l2 = [0]
输出:[0]
说明:
- 两个链表的节点数目范围是
[0, 50] -100 <= Node.val <= 100l1和l2均按 非递减顺序 排列
💡 解题思路
利用归并排序的思想,具体步骤如下:
- 使用哑节点
newHead构造一个头节点,并使用prev指向newHead用于遍历; - 然后判断
list1和list2头节点的值,将较小的头节点加入到合并后的链表中,并向后移动该链表的头节点指针; - 重复上一步操作,直到两个链表中出现链表为空的情况;
- 将剩余链表链接到合并后的链表中;
- 返回合并后有序链表的头节点
newHead.next。
💎 代码
👉 查看代码 👈
/**
* @param {ListNode} list1
* @param {ListNode} list2
* @return {ListNode}
*/
var mergeTwoLists = function (list1, list2) {
const newHead = new ListNode();
let prev = newHead;
while (list1 && list2) {
if (list1.val < list2.val) {
prev.next = list1;
list1 = list1.next;
} else {
prev.next = list2;
list2 = list2.next;
}
prev = prev.next;
}
prev.next = list1 != null ? list1 : list2;
return newHead.next;
};
#### 📌 [21. 合并两个有序链表 - LeetCode](https://wangfuyou.com/leetcode-js/problem/0021.html)
#### 💻 **题目大意**
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
**示例**:

> 输入:l1 = [1,2,4], l2 = [1,3,4]
>
> 输出:[1,1,2,3,4,4]
> 输入:l1 = [], l2 = []
>
> 输出:[]
> 输入:l1 = [], l2 = [0]
>
> 输出:[0]
**说明**:
- 两个链表的节点数目范围是 `[0, 50]`
- `-100 <= Node.val <= 100`
- `l1` 和 `l2` 均按 **非递减顺序** 排列
#### 💡 **解题思路**
利用归并排序的思想,具体步骤如下:
- 使用哑节点 `newHead` 构造一个头节点,并使用 `prev` 指向 `newHead` 用于遍历;
- 然后判断 `list1` 和 `list2` 头节点的值,将较小的头节点加入到合并后的链表中,并向后移动该链表的头节点指针;
- 重复上一步操作,直到两个链表中出现链表为空的情况;
- 将剩余链表链接到合并后的链表中;
- 返回合并后有序链表的头节点 `newHead.next`。
#### 💎 **代码**
<details>
<summary>👉 查看代码 👈</summary>
```javascript
/**
* @param {ListNode} list1
* @param {ListNode} list2
* @return {ListNode}
*/
var mergeTwoLists = function (list1, list2) {
const newHead = new ListNode();
let prev = newHead;
while (list1 && list2) {
if (list1.val < list2.val) {
prev.next = list1;
list1 = list1.next;
} else {
prev.next = list2;
list2 = list2.next;
}
prev = prev.next;
}
prev.next = list1 != null ? list1 : list2;
return newHead.next;
};
```
</details>
4. 删除链表倒数第 n 个节点
📌 19. 删除链表的倒数第 N 个节点 - LeetCode
💻 题目大意
给定一个链表的头节点 head ,删除链表的倒数第 n 个节点,并且返回链表的头节点。
示例:

输入:head = [1,2,3,4,5], n = 2
输出:[1,2,3,5]
输入:head = [1], n = 1
输出:[]
输入:head = [1,2], n = 1
输出:[1]
说明:
- 要求使用一次遍历实现
- 链表中节点的数目为
sz 1 ≤ sz ≤ 300 ≤ Node.val ≤ 1001 ≤ n ≤ sz
💡 解题思路
思路一:单指针
- 先遍历一遍链表,统计一下节点个数为
len,再遍历到len - n的位置,删除该位置上的节点; - 需要注意的一个特例是,有可能要删除头节点,在遍历之前,新建一个头节点,让其指向原来的头节点。
- 先遍历一遍链表,统计一下节点个数为
思路二:快慢指针
- 使用两个指针
slow、fast,都指向链表的头节点; - 让快指针
fast先走 n 步; - 再让快慢指针同时走,每次一步,等快指针遍历到链表尾部的时候,慢指针就刚好遍历到了倒数第 n 个节点位置;
- 将该位置上的节点删除即可。
- 使用两个指针
💎 代码
👉 查看代码 👈
/**
* @param {ListNode} head
* @param {number} n
* @return {ListNode}
*/
var removeNthFromEnd = function (head, n) {
let res = new ListNode(0, head);
let slow = res;
let fast = head;
while (n) {
fast = fast.next;
n--;
}
while (fast) {
slow = slow.next;
fast = fast.next;
}
slow.next = slow.next.next;
return res.next;
};
#### 📌 [19. 删除链表的倒数第 N 个节点 - LeetCode](https://wangfuyou.com/leetcode-js/problem/0019.html)
#### 💻 **题目大意**
给定一个链表的头节点 `head` ,删除链表的倒数第 `n` 个节点,并且返回链表的头节点。
**示例**:

> 输入:head = [1,2,3,4,5], n = 2
>
> 输出:[1,2,3,5]
> 输入:head = [1], n = 1
>
> 输出:[]
> 输入:head = [1,2], n = 1
>
> 输出:[1]
**说明**:
- 要求使用一次遍历实现
- 链表中节点的数目为 `sz`
- `1 ≤ sz ≤ 30`
- `0 ≤ Node.val ≤ 100`
- `1 ≤ n ≤ sz`
#### 💡 **解题思路**
- 思路一:单指针
- 先遍历一遍链表,统计一下节点个数为 `len`,再遍历到 `len - n` 的位置,删除该位置上的节点;
- 需要注意的一个特例是,有可能要删除头节点,在遍历之前,新建一个头节点,让其指向原来的头节点。
- 思路二:快慢指针
- 使用两个指针 `slow`、`fast`,都指向链表的头节点;
- 让快指针 `fast` 先走 n 步;
- 再让快慢指针同时走,每次一步,等快指针遍历到链表尾部的时候,慢指针就刚好遍历到了倒数第 n 个节点位置;
- 将该位置上的节点删除即可。
#### 💎 **代码**
<details>
<summary>👉 查看代码 👈</summary>
```javascript
/**
* @param {ListNode} head
* @param {number} n
* @return {ListNode}
*/
var removeNthFromEnd = function (head, n) {
let res = new ListNode(0, head);
let slow = res;
let fast = head;
while (n) {
fast = fast.next;
n--;
}
while (fast) {
slow = slow.next;
fast = fast.next;
}
slow.next = slow.next.next;
return res.next;
};
```
</details>
5. 求链表的中间节点
📌 876. 链表的中间节点 - LeetCode
💻 题目大意
给定一个单链表的头节点 head,返回链表的中间节点。如果有两个中间节点,则返回第二个中间节点。
示例:

输入:head = [1,2,3,4,5]
输出:[3,4,5]
解释:链表只有一个中间节点,值为 3 。

输入:head = [1,2,3,4,5,6]
输出:[4,5,6]
解释:该链表有两个中间节点,值分别为 3 和 4 ,返回第二个节点。
说明:
给定链表的节点数介于 1 和 100 之间。
💡 解题思路
思路一:单指针
- 先遍历一遍链表,统计一下节点个数为 n,再遍历到 n / 2 的位置,返回中间节点;
- 需要注意的一个特例是,有可能要删除头节点,在遍历之前,新建一个头节点,让其指向原来的头节点。
思路二:快慢指针
- 使用步长不一致的快慢指针进行一次遍历找到链表的中间节点;
- 使用两个指针
slow、fast,都指向链表的头节点; - 将快、慢指针同时向右移动,其中慢指针每次移动 1 步,即
slow = slow.next;快指针每次移动 2 步,即fast = fast.next.next; - 等到快指针移动到链表尾部(即
fast.next == null)时跳出循环体,此时 slow 指向链表中间位置; - 返回 slow 指针。
💎 代码
👉 查看代码 👈
/**
* @param {ListNode} head
* @return {ListNode}
*/
var middleNode = function (head) {
let slow = head;
let fast = head;
while (fast && fast.next) {
slow = slow.next;
fast = fast.next.next;
}
return slow;
};
#### 📌 [876. 链表的中间节点 - LeetCode](https://wangfuyou.com/leetcode-js/problem/0876.html)
#### 💻 **题目大意**
给定一个单链表的头节点 `head`,返回链表的中间节点。如果有两个中间节点,则返回第二个中间节点。
**示例**:

> 输入:head = [1,2,3,4,5]
>
> 输出:[3,4,5]
>
> 解释:链表只有一个中间节点,值为 3 。

> 输入:head = [1,2,3,4,5,6]
>
> 输出:[4,5,6]
>
> 解释:该链表有两个中间节点,值分别为 3 和 4 ,返回第二个节点。
**说明**:
给定链表的节点数介于 `1` 和 `100` 之间。
#### 💡 **解题思路**
- 思路一:单指针
- 先遍历一遍链表,统计一下节点个数为 n,再遍历到 n / 2 的位置,返回中间节点;
- 需要注意的一个特例是,有可能要删除头节点,在遍历之前,新建一个头节点,让其指向原来的头节点。
- 思路二:快慢指针
- 使用步长不一致的快慢指针进行一次遍历找到链表的中间节点;
- 使用两个指针 `slow`、`fast`,都指向链表的头节点;
- 将快、慢指针同时向右移动,其中慢指针每次移动 1 步,即 `slow = slow.next`;快指针每次移动 2 步,即 `fast = fast.next.next`;
- 等到快指针移动到链表尾部(即 `fast.next == null`)时跳出循环体,此时 slow 指向链表中间位置;
- 返回 slow 指针。
#### 💎 **代码**
<details>
<summary>👉 查看代码 👈</summary>
```javascript
/**
* @param {ListNode} head
* @return {ListNode}
*/
var middleNode = function (head) {
let slow = head;
let fast = head;
while (fast && fast.next) {
slow = slow.next;
fast = fast.next.next;
}
return slow;
};
```
</details>
6. LRU 缓存淘汰算法
另一个经典的链表应用场景,就是 LRU 缓存淘汰算法。
缓存是一种提高数据读取性能的技术,在硬件设计、软件开发中都有着非常广泛的应用,比如常见的 CPU 缓存、数据库缓存、浏览器缓存等等。
缓存的大小有限,当缓存被用满时,哪些数据应该被清理出去,哪些数据应该被保留?这就需要缓存淘汰策略来决定。常见的策略有三种:先进先出策略 FIFO(First In,First Out)、最少使用策略 LFU(Least Frequently Used)、最近最少使用策略 LRU(Least Recently Used)。
📌 146. LRU 缓存 - LeetCode
💻 题目大意
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现 LRUCache 类:
LRUCache(int capacity)以 正整数 作为容量capacity初始化 LRU 缓存int get(int key)如果关键字 key 存在于缓存中,则返回关键字的值,否则返回-1。void put(int key, int value)如果关键字key已经存在,则变更其数据值value;如果不存在,则向缓存中插入该组key-value。如果插入操作导致关键字数量超过capacity,则应该 逐出 最久未使用的关键字。- 函数
get和put必须以O(1)的平均时间复杂度运行。
示例:
// 输入
["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
// 输出
[null, null, null, 1, null, -1, null, -1, 3, 4]
// 解释
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
lRUCache.get(1); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
lRUCache.get(2); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
lRUCache.get(1); // 返回 -1 (未找到)
lRUCache.get(3); // 返回 3
lRUCache.get(4); // 返回 4
说明:
1 <= capacity <= 30000 <= key <= 100000 <= value <= 10^5- 最多调用
2 * 105次get和put
💡 解题思路
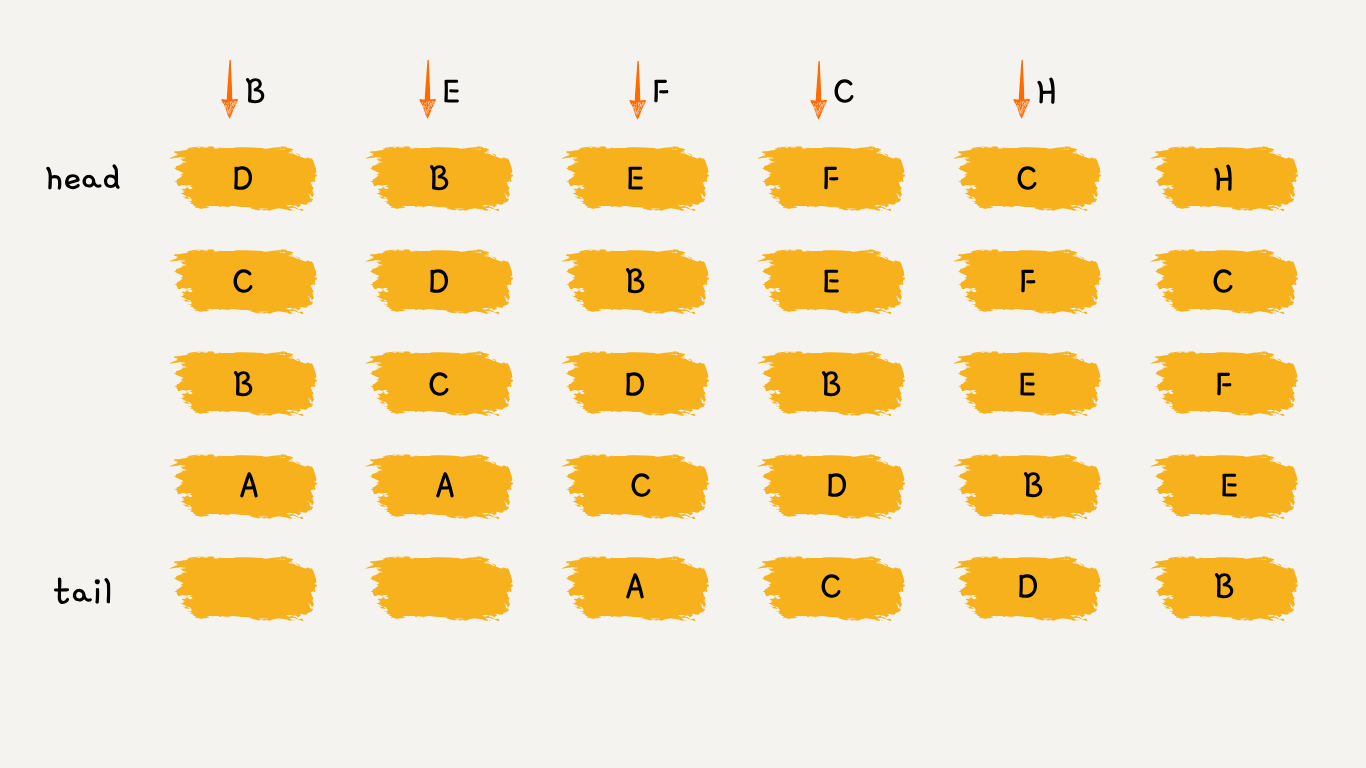
可以维护一个有序单链表,越靠近链表尾部的节点是越早之前访问的。如上图所示:
- 要插入 B 的时候,发现缓存中有 B ,这时需要把 B 放到链首,因为它被使用了;
- 要插入 E 的时候,缓存中没有 E,直接把 E 插入链首;
- 要插入 F 的时候,缓存中没有 F,容量已满,需要淘汰掉 A ,因为 A 最久未被使用;
- 要插入 C 的时候,发现缓存中有 C ,这时需要把 C 放到链首;
- 要插入 H 的时候,缓存中没有 H,容量已满,需要淘汰掉 D ,因为 D 最久未被使用;
可以发现,LRU 更新和插入新节点都发生在链首,删除数据都发生在链尾。
LRUCache 类有两个方法:
get当有一个新的数据被访问时:- 如果此数据之前已经被缓存在链表中了,遍历得到这个数据对应的节点,并将其从原来的位置删除,然后再插入到链表的头部,返回数据的值;
- 如果此数据没有在缓存链表中,则返回
-1;
put往链表里新增数据时:- 如果此数据之前已经被缓存在链表中了,更新此数据的值,并将其从原来的位置删除,再插入到链表的头部;
- 如果此数据没有在缓存链表中,又分为两种情况:
- 如果此时缓存未满,则将此节点直接插入到链表的头部;
- 如果此时缓存已满,则链表尾节点删除,将新的数据节点插入链表的头部。
这样就用链表实现了一个 LRU 缓存,如果使用单向链表实现,则缓存访问的时间复杂度为 O(n),因为不管缓存有没有满,都需要遍历一遍链表。
可以继续优化这个实现思路,比如使用双向链表,并引入 哈希表(Hash table) 来记录每个数据的位置,将缓存访问的时间复杂度降到 O(1)。
💎 代码
👉 查看代码 👈
class Node {
// @param {number} key
// @param {number} value
constructor(key, value) {
this.key = key;
this.value = value;
this.next = null;
this.prev = null;
}
}
class LRUCache {
// @param {number} capacity
constructor(capacity) {
this.cap = capacity;
this.cache = new Map();
this.head = new Node(0, 0);
this.tail = new Node(0, 0);
this.head.next = this.tail;
this.tail.prev = this.head;
}
// @param {number} key
// @return {number}
get(key) {
if (this.cache.has(key)) {
this.remove(this.cache.get(key));
this.insert(this.cache.get(key));
return this.cache.get(key).value;
}
return -1;
}
// @param {Node} node
remove(node) {
const prev = node.prev;
const next = node.next;
prev.next = next;
next.prev = prev;
}
// @param {Node} node
insert(node) {
const next = this.head.next;
this.head.next = node;
next.prev = node;
node.prev = this.head;
node.next = next;
}
// @param {number} key
// @param {number} value
// @return {void}
put(key, value) {
if (this.cache.has(key)) {
this.remove(this.cache.get(key));
}
this.cache.set(key, new Node(key, value));
this.insert(this.cache.get(key));
if (this.cache.size > this.cap) {
const old = this.tail.prev;
this.remove(old);
this.cache.delete(old.key);
}
}
}
/**
* Your LRUCache object will be instantiated and called as such:
* var obj = new LRUCache(capacity)
* var param_1 = obj.get(key)
* obj.put(key,value)
*/
#### 📌 [146. LRU 缓存 - LeetCode](https://wangfuyou.com/leetcode-js/problem/0146.html)
#### 💻 **题目大意**
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现 `LRUCache` 类:
- `LRUCache(int capacity)` 以 **正整数** 作为容量 `capacity` 初始化 LRU 缓存
- `int get(int key)` 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 `-1` 。
- `void put(int key, int value)` 如果关键字 `key` 已经存在,则变更其数据值 `value` ;如果不存在,则向缓存中插入该组 `key-value` 。如果插入操作导致关键字数量超过 `capacity` ,则应该 **逐出** 最久未使用的关键字。
- 函数 `get` 和 `put` 必须以 `O(1)` 的平均时间复杂度运行。
**示例**:
```js
// 输入
["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
// 输出
[null, null, null, 1, null, -1, null, -1, 3, 4]
// 解释
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
lRUCache.get(1); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
lRUCache.get(2); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
lRUCache.get(1); // 返回 -1 (未找到)
lRUCache.get(3); // 返回 3
lRUCache.get(4); // 返回 4
```
**说明**:
- `1 <= capacity <= 3000`
- `0 <= key <= 10000`
- `0 <= value <= 10^5`
- 最多调用 `2 * 105` 次 `get` 和 `put`
#### 💡 **解题思路**

可以维护一个有序单链表,越靠近链表尾部的节点是越早之前访问的。如上图所示:
- 要插入 B 的时候,发现缓存中有 B ,这时需要把 B 放到链首,因为它被使用了;
- 要插入 E 的时候,缓存中没有 E,直接把 E 插入链首;
- 要插入 F 的时候,缓存中没有 F,容量已满,需要淘汰掉 A ,因为 A 最久未被使用;
- 要插入 C 的时候,发现缓存中有 C ,这时需要把 C 放到链首;
- 要插入 H 的时候,缓存中没有 H,容量已满,需要淘汰掉 D ,因为 D 最久未被使用;
可以发现,LRU 更新和插入新节点都发生在链首,删除数据都发生在链尾。
`LRUCache` 类有两个方法:
- `get` 当有一个新的数据被访问时:
- 如果此数据之前已经被缓存在链表中了,遍历得到这个数据对应的节点,并将其从原来的位置删除,然后再插入到链表的头部,返回数据的值;
- 如果此数据没有在缓存链表中,则返回 `-1`;
- `put` 往链表里新增数据时:
- 如果此数据之前已经被缓存在链表中了,更新此数据的值,并将其从原来的位置删除,再插入到链表的头部;
- 如果此数据没有在缓存链表中,又分为两种情况:
- 如果此时缓存未满,则将此节点直接插入到链表的头部;
- 如果此时缓存已满,则链表尾节点删除,将新的数据节点插入链表的头部。
这样就用链表实现了一个 LRU 缓存,如果使用单向链表实现,则缓存访问的时间复杂度为 O(n),因为不管缓存有没有满,都需要遍历一遍链表。
可以继续优化这个实现思路,比如使用双向链表,并引入 **哈希表(Hash table)** 来记录每个数据的位置,将缓存访问的时间复杂度降到 `O(1)`。
#### 💎 **代码**
<details>
<summary>👉 查看代码 👈</summary>
```javascript
class Node {
// @param {number} key
// @param {number} value
constructor(key, value) {
this.key = key;
this.value = value;
this.next = null;
this.prev = null;
}
}
class LRUCache {
// @param {number} capacity
constructor(capacity) {
this.cap = capacity;
this.cache = new Map();
this.head = new Node(0, 0);
this.tail = new Node(0, 0);
this.head.next = this.tail;
this.tail.prev = this.head;
}
// @param {number} key
// @return {number}
get(key) {
if (this.cache.has(key)) {
this.remove(this.cache.get(key));
this.insert(this.cache.get(key));
return this.cache.get(key).value;
}
return -1;
}
// @param {Node} node
remove(node) {
const prev = node.prev;
const next = node.next;
prev.next = next;
next.prev = prev;
}
// @param {Node} node
insert(node) {
const next = this.head.next;
this.head.next = node;
next.prev = node;
node.prev = this.head;
node.next = next;
}
// @param {number} key
// @param {number} value
// @return {void}
put(key, value) {
if (this.cache.has(key)) {
this.remove(this.cache.get(key));
}
this.cache.set(key, new Node(key, value));
this.insert(this.cache.get(key));
if (this.cache.size > this.cap) {
const old = this.tail.prev;
this.remove(old);
this.cache.delete(old.key);
}
}
}
/**
* Your LRUCache object will be instantiated and called as such:
* var obj = new LRUCache(capacity)
* var param_1 = obj.get(key)
* obj.put(key,value)
*/
```
</details>
链表排序
#### 📌 [148. 链表排序 - LeetCode](https://wangfuyou.com/leetcode-js/problem/0148.html)
常见的排序算法有:冒泡排序、选择排序、插入排序、希尔排序、归并排序、快速排序、堆排序、计数排序、桶排序、基数排序等。
对于链表排序,由于链表不支持随机访问,访问链表后面的节点只能依靠 next 指针从头部顺序遍历,所以链表排序问题会比数组排序更加复杂一点。
- 适合链表的排序算法:冒泡排序、选择排序、插入排序、归并排序、快速排序、桶排序、计数排序、基数排序;
- 不适合链表的排序算法:希尔排序;
- 可以用于链表排序但不建议使用的排序算法:堆排序;
- 重点掌握:插入排序、归并排序;
1. 冒泡排序
使用三个指针
node_i、node_j和tail。其中node_i用于控制外循环次数,循环次数为链节点个数(链表长度)。node_j和tail用于控制内循环次数和循环结束位置。排序开始前,将
node_i、node_j置于头节点位置。tail指向链表末尾,即None。比较链表中相邻两个元素
node_j.val与node_j.next.val的值大小,如果node_j.val > node_j.next.val,则值相互交换。否则不发生交换。然后向右移动node_j指针,直到node_j.next == tail时停止。一次循环之后,将
tail移动到node_j所在位置。相当于tail向左移动了一位。此时tail节点右侧为链表中最大的链节点。然后移动
node_i节点,并将node_j置于头节点位置。然后重复第 3、4 步操作。直到
node_i节点移动到链表末尾停止,排序结束。返回链表的头节点
head。
- 时间复杂度:
O(n^2)。 - 空间复杂度:
O(1)。
👉 查看代码 👈
class Solution:
def bubbleSort(self, head: ListNode):
node_i = head
tail = None
# 外层循环次数为 链表节点个数
while node_i:
node_j = head
while node_j and node_j.next != tail:
if node_j.val > node_j.next.val:
# 交换两个节点的值
node_j.val, node_j.next.val = node_j.next.val, node_j.val
node_j = node_j.next
# 尾指针向前移动 1 位,此时尾指针右侧为排好序的链表
tail = node_j
node_i = node_i.next
return head
def sortList(self, head: Optional[ListNode]) -> Optional[ListNode]:
return self.bubbleSort(head)
2. 选择排序
- 使用两个指针
node_i、node_j。node_i既可以用于控制外循环次数,又可以作为当前未排序链表的第一个链节点位置。 - 使用
min_node记录当前未排序链表中值最小的链节点。 - 每一趟排序开始时,先令
min_node = node_i(即暂时假设链表中node_i节点为值最小的节点,经过比较后再确定最小值节点位置)。 - 然后依次比较未排序链表中
node_j.val与min_node.val的值大小。如果node_j.val < min_node.val,则更新min_node为node_j。 - 这一趟排序结束时,未排序链表中最小值节点为
min_node,如果node_i != min_node,则将node_i与min_node值进行交换。如果node_i == min_node,则不用交换。 - 排序结束后,继续向右移动
node_i,重复上述步骤,在剩余未排序链表中寻找最小的链节点,并与node_i进行比较和交换,直到node_i == None或者node_i.next == None时,停止排序。 - 返回链表的头节点
head。
- 时间复杂度:
O(n^2) - 空间复杂度:
O(1)
👉 查看代码 👈
class Solution:
def sectionSort(self, head: ListNode):
node_i = head
# node_i 为当前未排序链表的第一个链节点
while node_i and node_i.next:
# min_node 为未排序链表中的值最小节点
min_node = node_i
node_j = node_i.next
while node_j:
if node_j.val < min_node.val:
min_node = node_j
node_j = node_j.next
# 交换值最小节点与未排序链表中第一个节点的值
if node_i != min_node:
node_i.val, min_node.val = min_node.val, node_i.val
node_i = node_i.next
return head
def sortList(self, head: Optional[ListNode]) -> Optional[ListNode]:
return self.sectionSort(head)
3. 插入排序
先使用哑节点
dummy_head构造一个指向head的指针,使得可以从head开始遍历。维护
sorted_list为链表的已排序部分的最后一个节点,初始时,sorted_list = head。维护
prev为插入元素位置的前一个节点,维护cur为待插入元素。初始时,prev = head,cur = head.next。比较
sorted_list和cur的节点值。- 如果
sorted_list.val <= cur.val,说明cur应该插入到sorted_list之后,则将sorted_list后移一位。 - 如果
sorted_list.val > cur.val,说明cur应该插入到head与sorted_list之间。则使用prev从head开始遍历,直到找到插入cur的位置的前一个节点位置。然后将cur插入。
- 如果
令
cur = sorted_list.next,此时cur为下一个待插入元素。重复 4、5 步骤,直到
cur遍历结束为空。返回dummy_head的下一个节点。
- 时间复杂度:
O(n^2) - 空间复杂度:
O(1)
👉 查看代码 👈
class Solution:
def insertionSort(self, head: ListNode):
if not head or not head.next:
return head
dummy_head = ListNode(-1)
dummy_head.next = head
sorted_list = head
cur = head.next
while cur:
if sorted_list.val <= cur.val:
# 将 cur 插入到 sorted_list 之后
sorted_list = sorted_list.next
else:
prev = dummy_head
while prev.next.val <= cur.val:
prev = prev.next
# 将 cur 到链表中间
sorted_list.next = cur.next
cur.next = prev.next
prev.next = cur
cur = sorted_list.next
return dummy_head.next
def sortList(self, head: Optional[ListNode]) -> Optional[ListNode]:
return self.insertionSort(head)
4. 归并排序
- 分割环节:找到链表中心链节点,从中心节点将链表断开,并递归进行分割。
- 使用快慢指针
fast = head.next、slow = head,让fast每次移动2步,slow移动1步,移动到链表末尾,从而找到链表中心链节点,即slow。 - 从中心位置将链表从中心位置分为左右两个链表
left_head和right_head,并从中心位置将其断开,即slow.next = None。 - 对左右两个链表分别进行递归分割,直到每个链表中只包含一个链节点。
- 使用快慢指针
- 归并环节:将递归后的链表进行两两归并,完成一遍后每个子链表长度加倍。重复进行归并操作,直到得到完整的链表。
- 使用哑节点
dummy_head构造一个头节点,并使用cur指向dummy_head用于遍历。 - 比较两个链表头节点
left和right的值大小。将较小的头节点加入到合并后的链表中。并向后移动该链表的头节点指针。 - 然后重复上一步操作,直到两个链表中出现链表为空的情况。
- 将剩余链表插入到合并中的链表中。
- 将哑节点
dummy_dead的下一个链节点dummy_head.next作为合并后的头节点返回。
- 使用哑节点
- 时间复杂度:
O(nlogn) - 空间复杂度:
O(1)
👉 查看代码 👈
class Solution:
def merge(self, left, right):
# 归并环节
dummy_head = ListNode(-1)
cur = dummy_head
while left and right:
if left.val <= right.val:
cur.next = left
left = left.next
else:
cur.next = right
right = right.next
cur = cur.next
if left:
cur.next = left
elif right:
cur.next = right
return dummy_head.next
def mergeSort(self, head: ListNode):
# 分割环节
if not head or not head.next:
return head
# 快慢指针找到中心链节点
slow, fast = head, head.next
while fast and fast.next:
slow = slow.next
fast = fast.next.next
# 断开左右链节点
left_head, right_head = head, slow.next
slow.next = None
# 归并操作
return self.merge(self.mergeSort(left_head), self.mergeSort(right_head))
def sortList(self, head: Optional[ListNode]) -> Optional[ListNode]:
return self.mergeSort(head)
5. 快速排序
- 从链表中找到一个基准值
pivot,这里以头节点为基准值。 - 然后通过快慢指针
node_i、node_j在链表中移动,使得node_i之前的节点值都小于基准值,node_i之后的节点值都大于基准值。从而把数组拆分为左右两个部分。 - 再对左右两个部分分别重复第二步,直到各个部分只有一个节点,则排序结束。
注意:
虽然链表快速排序算法的平均时间复杂度为
O(nlogn)。但链表快速排序算法中基准值pivot的取值做不到数组快速排序算法中的随机选择。一旦给定序列是有序链表,时间复杂度就会退化到O(n^2)。这也是这道题目使用链表快速排序容易超时的原因。
- 时间复杂度:
O(nlogn) - 空间复杂度:
O(1)
👉 查看代码 👈
class Solution:
def partition(self, left: ListNode, right: ListNode):
# 左闭右开,区间没有元素或者只有一个元素,直接返回第一个节点
if left == right or left.next == right:
return left
# 选择头节点为基准节点
pivot = left.val
# 使用 node_i, node_j 双指针,保证 node_i 之前的节点值都小于基准节点值,node_i 与 node_j 之间的节点值都大于等于基准节点值
node_i, node_j = left, left.next
while node_j != right:
# 发现一个小与基准值的元素
if node_j.val < pivot:
# 因为 node_i 之前节点都小于基准值,所以先将 node_i 向右移动一位(此时 node_i 节点值大于等于基准节点值)
node_i = node_i.next
# 将小于基准值的元素 node_j 与当前 node_i 换位,换位后可以保证 node_i 之前的节点都小于基准节点值
node_i.val, node_j.val = node_j.val, node_i.val
node_j = node_j.next
# 将基准节点放到正确位置上
node_i.val, left.val = left.val, node_i.val
return node_i
def quickSort(self, left: ListNode, right: ListNode):
if left == right or left.next == right:
return left
pi = self.partition(left, right)
self.quickSort(left, pi)
self.quickSort(pi.next, right)
return left
def sortList(self, head: Optional[ListNode]) -> Optional[ListNode]:
if not head or not head.next:
return head
return self.quickSort(head, None)
6. 桶排序
- 使用
cur指针遍历一遍链表。找出链表中最大值list_max和最小值list_min。 - 通过
(最大值 - 最小值) / 每个桶的大小计算出桶的个数,即bucket_count = (list_max - list_min) // bucket_size + 1个桶。 - 定义数组
buckets为桶,桶的个数为bucket_count个。 - 使用
cur指针再次遍历一遍链表,将每个元素装入对应的桶中。 - 对每个桶内的元素单独排序,可以使用链表插入排序(超时)、链表归并排序(通过)、链表快速排序(超时)等算法。
- 最后按照顺序将桶内的元素拼成新的链表,并返回。
- 时间复杂度:
O(n) - 空间复杂度:
O(n + m)。m为桶的个数
👉 查看代码 👈
class ListNode:
def __init__(self, val=0, next=None):
self.val = val
self.next = next
class Solution:
# 将链表节点值 val 添加到对应桶 buckets[index] 中
def insertion(self, buckets, index, val):
if not buckets[index]:
buckets[index] = ListNode(val)
return
node = ListNode(val)
node.next = buckets[index]
buckets[index] = node
# 归并环节
def merge(self, left, right):
dummy_head = ListNode(-1)
cur = dummy_head
while left and right:
if left.val <= right.val:
cur.next = left
left = left.next
else:
cur.next = right
right = right.next
cur = cur.next
if left:
cur.next = left
elif right:
cur.next = right
return dummy_head.next
def mergeSort(self, head: ListNode):
# 分割环节
if not head or not head.next:
return head
# 快慢指针找到中心链节点
slow, fast = head, head.next
while fast and fast.next:
slow = slow.next
fast = fast.next.next
# 断开左右链节点
left_head, right_head = head, slow.next
slow.next = None
# 归并操作
return self.merge(self.mergeSort(left_head), self.mergeSort(right_head))
def bucketSort(self, head: ListNode, bucket_size=5):
if not head:
return head
# 找出链表中最大值 list_max 和最小值 list_min
list_min, list_max = float('inf'), float('-inf')
cur = head
while cur:
if cur.val < list_min:
list_min = cur.val
if cur.val > list_max:
list_max = cur.val
cur = cur.next
# 计算桶的个数,并定义桶
bucket_count = (list_max - list_min) // bucket_size + 1
buckets = [[] for _ in range(bucket_count)]
# 将链表节点值依次添加到对应桶中
cur = head
while cur:
index = (cur.val - list_min) // bucket_size
self.insertion(buckets, index, cur.val)
cur = cur.next
dummy_head = ListNode(-1)
cur = dummy_head
# 将元素依次出桶,并拼接成有序链表
for bucket_head in buckets:
bucket_cur = self.mergeSort(bucket_head)
while bucket_cur:
cur.next = bucket_cur
cur = cur.next
bucket_cur = bucket_cur.next
return dummy_head.next
def sortList(self, head: Optional[ListNode]) -> Optional[ListNode]:
return self.bucketSort(head)
7. 计数排序
- 使用
cur指针遍历一遍链表。找出链表中最大值list_max和最小值list_min。 - 使用数组
counts存储节点出现次数。 - 再次使用
cur指针遍历一遍链表。将链表中每个值为cur.val的节点出现次数,存入数组对应第cur.val - list_min项中。 - 反向填充目标链表:
- 建立一个哑节点
dummy_head,作为链表的头节点。使用cur指针指向dummy_head。 - 从小到大遍历一遍数组
counts。对于每个counts[i] != 0的元素建立一个链节点,值为i + list_min,将其插入到cur.next上。并向右移动cur。同时counts[i] -= 1。直到counts[i] == 0后继续向后遍历数组counts。
- 建立一个哑节点
- 将哑节点
dummy_dead的下一个链节点dummy_head.next作为新链表的头节点返回。
- 时间复杂度:
O(n + k),其中k代表待排序链表中所有元素的值域 - 空间复杂度:
O(k)
👉 查看代码 👈
class Solution:
def countingSort(self, head: ListNode):
if not head:
return head
# 找出链表中最大值 list_max 和最小值 list_min
list_min, list_max = float('inf'), float('-inf')
cur = head
while cur:
if cur.val < list_min:
list_min = cur.val
if cur.val > list_max:
list_max = cur.val
cur = cur.next
size = list_max - list_min + 1
counts = [0 for _ in range(size)]
cur = head
while cur:
counts[cur.val - list_min] += 1
cur = cur.next
dummy_head = ListNode(-1)
cur = dummy_head
for i in range(size):
while counts[i]:
cur.next = ListNode(i + list_min)
counts[i] -= 1
cur = cur.next
return dummy_head.next
def sortList(self, head: Optional[ListNode]) -> Optional[ListNode]:
return self.countingSort(head)
8. 基数排序
- 使用
cur指针遍历链表,获取节点值位数最长的位数size。 - 从个位到高位遍历位数。因为
0~9共有10位数字,所以建立10个桶。 - 以每个节点对应位数上的数字为索引,将节点值放入到对应桶中。
- 建立一个哑节点
dummy_head,作为链表的头节点。使用cur指针指向dummy_head。 - 将桶中元素依次取出,并根据元素值建立链表节点,并插入到新的链表后面。从而生成新的链表。
- 之后依次以十位,百位,…,直到最大值元素的最高位处值为索引,放入到对应桶中,并生成新的链表,最终完成排序。
- 将哑节点
dummy_dead的下一个链节点dummy_head.next作为新链表的头节点返回。
- 时间复杂度:
O(n * k)。其中n是待排序元素的个数,k是数字位数。k的大小取决于数字位的选择(十进制位、二进制位)和待排序元素所属数据类型全集的大小。 - 空间复杂度:
O(n + k)
👉 查看代码 👈
class Solution:
def radixSort(self, head: ListNode):
# 计算位数最长的位数
size = 0
cur = head
while cur:
val_len = len(str(cur.val))
if val_len > size:
size = val_len
cur = cur.next
# 从个位到高位遍历位数
for i in range(size):
buckets = [[] for _ in range(10)]
cur = head
while cur:
# 以每个节点对应位数上的数字为索引,将节点值放入到对应桶中
buckets[cur.val // (10 ** i) % 10].append(cur.val)
cur = cur.next
# 生成新的链表
dummy_head = ListNode(-1)
cur = dummy_head
for bucket in buckets:
for num in bucket:
cur.next = ListNode(num)
cur = cur.next
head = dummy_head.next
return head
def sortList(self, head: Optional[ListNode]) -> Optional[ListNode]:
return self.radixSort(head)
复杂度分析
| 排序算法 | 平均时间复杂度 | 空间复杂度 | 排序方式 | 稳定性 | 备注 |
|---|---|---|---|---|---|
| 冒泡排序 | O(n^2) | O(1) | in-place | 稳定 | |
| 选择排序 | O(n^2) | O(1) | in-place | 不稳定 | |
| 插入排序 | O(n^2) | O(1) | in-place | 稳定 | |
| 归并排序 | O(nlogn) | O(1) | out-place | 稳定 | |
| 快速排序 | O(nlogn) | O(1) | in-place | 不稳定 | |
| 桶排序 | O(n) | O(n+k) | out-place | 稳定 | k 为桶的个数 |
| 计数排序 | O(n+k) | O(k) | out-place | 稳定 | k 为待排序链表中所有元素的值域 |
| 基数排序 | O(n*k) | O(n+k) | out-place | 稳定 | k 为数字位数 |
希尔排序为什么不适合链表排序?
希尔排序:希尔排序中经常涉及到对序列中第 i + gap 的元素进行操作,其中 gap 是希尔排序中当前的步长。而链表不支持随机访问的特性,导致这种操作不适合链表,因而希尔排序算法不适合进行链表排序。
为什么不建议使用堆排序?
堆排序:堆排序所使用的最大堆 / 最小堆结构本质上是一棵完全二叉树。而完全二叉树适合采用顺序存储结构(数组)。因为数组存储的完全二叉树可以很方便的通过下标序号来确定父亲节点和孩子节点,并且可以极大限度的节省存储空间。
而链表用在存储完全二叉树的时候,因为不支持随机访问的特性,导致其寻找子节点和父亲节点会比较耗时,如果增加指向父亲节点的变量,又会浪费大量存储空间。所以堆排序算法不适合进行链表排序。
如果一定要对链表进行堆排序,则可以使用额外的数组空间表示堆结构。然后将链表中各个节点的值依次添加入堆结构中,对数组进行堆排序。排序后,再按照堆中元素顺序,依次建立链表节点,构建新的链表并返回新链表头节点。
链表的技巧
想要写好链表代码并不是容易的事儿,尤其是那些复杂的链表操作,比如链表反转、有序链表合并等,写的时候非常容易出错。面试中,能把“链表反转”这几行代码写对的人不足 10%。
下面总结了几个写链表代码的技巧,如果能熟练掌握这几个技巧,再加以练习,轻松拿下链表代码完全没有问题。
1. 理解指针或引用的含义
将某个变量赋值给指针,实际上就是将这个变量的地址赋值给指针,或者反过来说,指针中存储了这个变量的内存地址,指向了这个变量,通过指针就能找到这个变量。
在编写链表代码的时候,经常会有这样的代码:p.next = q,这行代码是说,p节点中的next指针存储了q节点的内存地址。
还有:p.next = p.next.next,这行代码表示,p节点的next指针存储了p节点的下下一个节点的内存地址。
2. 警惕指针丢失和内存泄漏
写链表代码的时候,指针指来指去,一会儿就不知道指到哪里了。所以一定注意不要弄丢了指针。
比如单链表的插入操作,希望在节点a和相邻的节点b之间插入节点x,假设当前指针p指向节点a。如果我们将代码实现变成下面这个样子,就会发生指针丢失和内存泄露。
p.next = x; // 将p的next指针指向x节点;
x.next = p.next; // 将x的节点的next指针指向b节点;
p.next指针在完成第一步操作之后,已经不再指向节点b了,而是指向节点x。第 2 行代码相当于将x赋值给x.next,自己指向自己。因此,整个链表也就断成了两半,从节点 b 往后的所有节点都无法访问到了。
所以,插入节点时,一定要注意操作的顺序,要先将节点 x 的 next 指针指向节点 b,再把节点 a 的 next 指针指向节点 x,这样才不会丢失指针,导致内存泄漏。
对于刚刚的插入代码,只需要把第 1 行和第 2 行代码的顺序颠倒一下就可以了。
3. 重点留意边界条件处理
在编写的过程中以及编写完成之后,要检查一下代码在边界条件下是否能正确运行。常见的检查链表代码是否正确的边界条件有这些:
- 如果链表为空时,代码是否能正常工作?
- 如果链表只包含一个节点时,代码是否能正常工作?
- 如果链表只包含两个节点时,代码是否能正常工作?
- 代码逻辑在处理头节点和尾节点的时候,是否能正常工作?
4. 举例法和画图法,辅助思考
对于稍微复杂的链表操作,比如前面单链表反转,指针一会儿指这,一会儿指那,一会儿就被绕晕了。
所以这时可以使用举例法和画图法。可以把各种情况都举一个例子,把它画在纸上,画出插入前和插入后的链表变化。
相关题目
链表基础题目
| 题号 | 标题 | 题解 | 标签 | 难度 | 力扣 |
|---|---|---|---|---|---|
| 707 | 设计链表 | [✓] | 设计 链表 | 🟠 | 🀄️ 🔗 |
| 83 | 删除排序链表中的重复元素 | [✓] | 链表 | 🟢 | 🀄️ 🔗 |
| 82 | 删除排序链表中的重复元素 II | [✓] | 链表 双指针 | 🟠 | 🀄️ 🔗 |
| 206 | 反转链表 | [✓] | 递归 链表 | 🟢 | 🀄️ 🔗 |
| 92 | 反转链表 II | [✓] | 链表 | 🟠 | 🀄️ 🔗 |
| 25 | K 个一组翻转链表 | [✓] | 递归 链表 | 🔴 | 🀄️ 🔗 |
| 203 | 移除链表元素 | [✓] | 递归 链表 | 🟢 | 🀄️ 🔗 |
| 328 | 奇偶链表 | [✓] | 链表 | 🟠 | 🀄️ 🔗 |
| 234 | 回文链表 | [✓] | 栈 递归 链表 1+ | 🟢 | 🀄️ 🔗 |
| 430 | 扁平化多级双向链表 | [✓] | 深度优先搜索 链表 双向链表 | 🟠 | 🀄️ 🔗 |
| 138 | 随机链表的复制 | [✓] | 哈希表 链表 | 🟠 | 🀄️ 🔗 |
| 61 | 旋转链表 | [✓] | 链表 双指针 | 🟠 | 🀄️ 🔗 |
链表排序
| 题号 | 标题 | 题解 | 标签 | 难度 | 力扣 |
|---|---|---|---|---|---|
| 148 | 排序链表 | [✓] | 链表 双指针 分治 2+ | 🟠 | 🀄️ 🔗 |
| 21 | 合并两个有序链表 | [✓] | 递归 链表 | 🟢 | 🀄️ 🔗 |
| 23 | 合并 K 个升序链表 | [✓] | 链表 分治 堆(优先队列) 1+ | 🔴 | 🀄️ 🔗 |
| 147 | 对链表进行插入排序 | [✓] | 链表 排序 | 🟠 | 🀄️ 🔗 |
链表双指针
| 题号 | 标题 | 题解 | 标签 | 难度 | 力扣 |
|---|---|---|---|---|---|
| 141 | 环形链表 | [✓] | 哈希表 链表 双指针 | 🟢 | 🀄️ 🔗 |
| 142 | 环形链表 II | [✓] | 哈希表 链表 双指针 | 🟠 | 🀄️ 🔗 |
| 160 | 相交链表 | [✓] | 哈希表 链表 双指针 | 🟢 | 🀄️ 🔗 |
| 19 | 删除链表的倒数第 N 个结点 | [✓] | 链表 双指针 | 🟠 | 🀄️ 🔗 |
| 876 | 链表的中间结点 | [✓] | 链表 双指针 | 🟢 | 🀄️ 🔗 |
| 剑指 Offer 22 | 链表中倒数第k个节点 | [✓] | 链表 双指针 | 🟢 | 🀄️ |
| 143 | 重排链表 | [✓] | 栈 递归 链表 1+ | 🟠 | 🀄️ 🔗 |
| 2 | 两数相加 | [✓] | 递归 链表 数学 | 🟠 | 🀄️ 🔗 |
| 445 | 两数相加 II | [✓] | 栈 链表 数学 | 🟠 | 🀄️ 🔗 |