2. 粗略估算
2. 粗略估算
在系统设计面试中,有时会被要求估算性能要求或系统容量,这些通常是通过思维实验和常见的性能数据进行估算的。(by Jeff Dean - Google 资深工程师)
要有效地进行这种估算,有一些机制是我们需要了解的。
二的幂
数据量可能非常庞大,但计算归结为基础的数学。
为了进行精确计算,您需要了解二的幂,它与给定的数据单位对应:
- 2^10 == ~1000 == 1kb
- 2^20 == ~1 百万 == 1mb
- 2^30 == ~10 亿 == 1gb
- 2^40 == ~1 万亿 == 1tb
- 2^50 == ~1 千万亿 == 1pb
每个程序员应了解的延迟数值
有一个广为人知的表格,列出了典型计算机操作的持续时间,由 Jeff Dean 创建。
由于硬件的改进,这些数值可能略显过时,但它们仍然提供了操作之间的相对度量:
- L1 缓存访问 == 0.5ns
- 分支预测错误 == 5ns
- L2 缓存访问 == 7ns
- 互斥锁的锁定/解锁 == 100ns
- 主内存访问 == 100ns
- 压缩 1kb == 10,000ns == 10 微秒
- 通过 1gbps 网络发送 2kb == 20,000ns == 20 微秒
- 从内存中顺序读取 1mb == 250 微秒
- 同一数据中心的往返 == 500 微秒
- 硬盘寻址 == 10 毫秒
- 从网络顺序读取 1mb == 10 毫秒
- 从硬盘顺序读取 1mb == 30 毫秒
- 从加利福尼亚发送数据包到荷兰再返回加利福尼亚 == 150 毫秒
一个很好的可视化图:
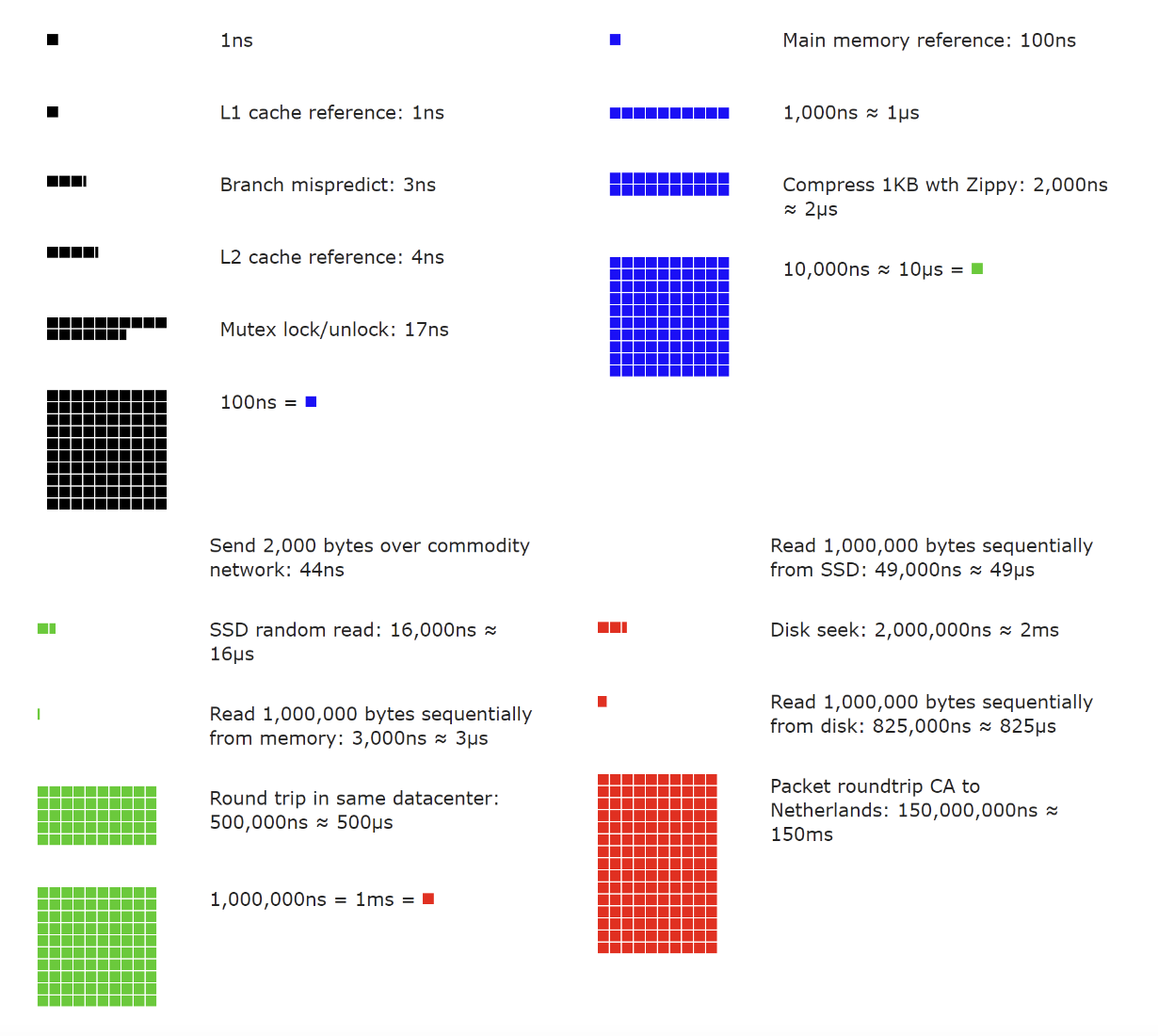
从上述数值中可以得出一些结论:
- 内存很快,硬盘很慢
- 如果可能,避免硬盘寻址
- 压缩通常很快
- 如果可能,发送数据前先压缩
- 数据中心的往返延迟较贵
可用性数值
高可用性 == 系统持续可操作的能力。换句话说,就是最小化停机时间。
通常,服务的可用性目标在 99%到 100%之间。
SLA(服务水平协议)是服务提供商和客户之间的正式协议。它正式定义了您的服务需要支持的正常运行时间水平。
云服务提供商通常将其正常运行时间定为 99.9%或更高。例如,AWS EC2 的 SLA 为 99.99%。
以下是不同 SLA 下允许的停机时间总结:

示例 - 估算 Twitter 的 QPS 和存储需求
假设:
- 3 亿月活跃用户(MAU)
- 50%的用户每天使用 Twitter
- 用户平均每天发布 2 条推文
- 10%的推文包含媒体
- 数据存储 5 年
估算:
- 写入请求每秒(RPS)估算:
- (150 百万 * 2) / (24 小时 * 60 分钟 * 60 秒) = 每秒 3400-3600 条推文
- 峰值=7000TPS
- 媒体存储量估算:
- 每天媒体文件存储量 300 百万 * 10% == 30 百万
- 如果假设每个媒体文件为 1MB -> 30 百万 * 1MB = 每天 30TB
- 5 年后 -> 30TB * 365 * 5 == 55PB
- 推文存储估算:
- 1 条推文:64 字节 ID + 140 字节文本 + 1000 字节元数据 == 1MB
- 每天写入推文:3500 * 60 * 60 * 24 = 302MB
- 5 年后 -> 302MB * 365 * 5 == 551GB
提示
粗略估算关注的是过程,而非结果。面试官可能会测试你的问题解决能力。
一些提示供您参考:
- 四舍五入和近似——不要试图计算 99987/9.1,而是四舍五入为 100000/10,这样更容易计算。
- 在进行估算之前,先写下您的假设
- 明确标记单位,写作 5MB,而不是仅写 5。
- 常见的估算问题——QPS(每秒查询次数)、峰值 QPS、存储、缓存、服务器数量。