2756. 批处理查询 🔒
2756. 批处理查询 🔒
题目
Batching multiple small queries into a single large query can be a useful optimization. Write a class QueryBatcher that implements this functionality.
The constructor should accept two parameters:
- An asynchronous function
queryMultiplewhich accepts an array of string keysinput. It will resolve with an array of values that is the same length as the input array. Each index corresponds to the value associated withinput[i]. You can assume the promise will never reject. - A throttle time in milliseconds
t.
The class has a single method.
async getValue(key). Accepts a single string key and resolves with a single string value. The keys passed to this function should eventually get passed to thequeryMultiplefunction.queryMultipleshould never be called consecutively withintmilliseconds. The first timegetValueis called,queryMultipleshould immediately be called with that single key. If aftertmilliseconds,getValuehad been called again, all the passed keys should be passed toqueryMultipleand ultimately returned. You can assume every key passed to this method is unique.
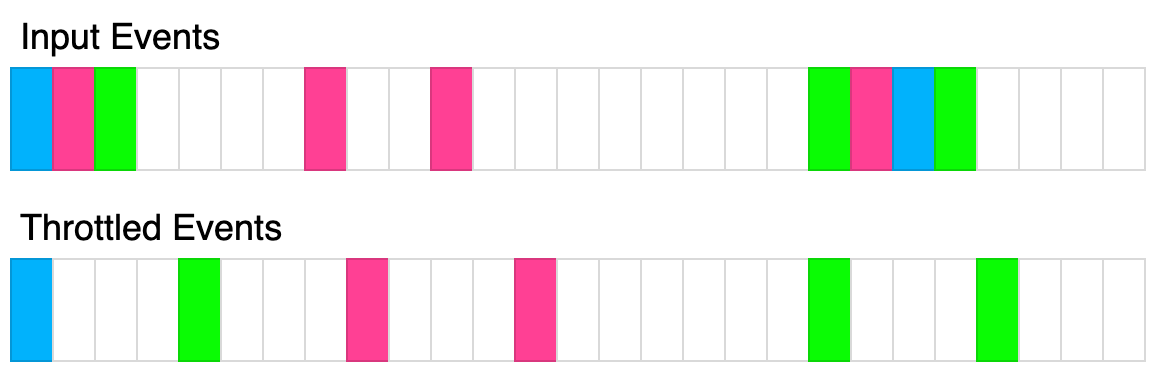
The following diagram illustrates how the throttling algorithm works. Each rectangle represents 100ms. The throttle time is 400ms.
Example 1:
Input:
queryMultiple = async function (keys) { return keys.map((key) => key + '!'); }; t = 100; calls = [ { key: 'a', time: 10 }, { key: 'b', time: 20 }, { key: 'c', time: 30 } ];Output:
[ { resolved: 'a!', time: 10 }, { resolved: 'b!', time: 110 }, { resolved: 'c!', time: 110 } ];Explanation:
const batcher = new QueryBatcher(queryMultiple, 100); setTimeout(() => batcher.getValue('a'), 10); // "a!" at t=10ms setTimeout(() => batcher.getValue('b'), 20); // "b!" at t=110ms setTimeout(() => batcher.getValue('c'), 30); // "c!" at t=110msqueryMultiple simply adds an "!" to the key
At t=10ms, getValue('a') is called, queryMultiple(['a']) is immediately called and the result is immediately returned.
At t=20ms, getValue('b') is called but the query is queued
At t=30ms, getValue('c') is called but the query is queued.
At t=110ms, queryMultiple(['a', 'b']) is called and the results are immediately returned.
Example 2:
Input:
queryMultiple = async function (keys) { await new Promise((res) => setTimeout(res, 100)); return keys.map((key) => key + '!'); }; t = 100; calls = [ { key: 'a', time: 10 }, { key: 'b', time: 20 }, { key: 'c', time: 30 } ];Output:
[ { resolved: 'a!', time: 110 }, { resolved: 'b!', time: 210 }, { resolved: 'c!', time: 210 } ];Explanation:
This example is the same as example 1 except there is a 100ms delay in queryMultiple. The results are the same except the promises resolve 100ms later.
Example 3:
Input:
queryMultiple = async function(keys) { await new Promise(res => setTimeout(res, keys.length * 100)); return keys.map(key => key + '!'); } t = 100 calls = [ {"key": "a", "time": 10}, {"key": "b", "time": 20}, {"key": "c", "time": 30}, {"key": "d", "time": 40}, {"key": "e", "time": 250} {"key": "f", "time": 300} ]Output:
[ { resolved: 'a!', time: 110 }, { resolved: 'e!', time: 350 }, { resolved: 'b!', time: 410 }, { resolved: 'c!', time: 410 }, { resolved: 'd!', time: 410 }, { resolved: 'f!', time: 450 } ];Explanation: queryMultiple(['a']) is called at t=10ms, it is resolved at t=110ms
queryMultiple(['b', 'c', 'd']) is called at t=110ms, it is resolved at 410ms queryMultiple(['e']) is called at t=250ms, it is resolved at 350ms queryMultiple(['f']) is called at t=350ms, it is resolved at 450ms
Constraints:
0 <= t <= 10000 <= calls.length <= 101 <= key.length <= 100- All keys are unique
题目大意
将多个小查询批处理为单个大查询可以是一种有用的优化。请编写一个名为 QueryBatcher 的类来实现这个功能。
它的构造函数应接受两个参数:
- 一个异步函数
queryMultiple,它接受一个字符串键的数组作为输入。它将返回一个与输入数组长度相同的值数组。每个索引对应于与input[i]相关联的值。可以假设该异步函数永远不会被拒绝。 - 一个以毫秒为单位的节流时间
t。
该类有一个方法:
async getValue(key):接受一个字符串键,并返回一个解析后的字符串值。传递给此函数的键值最终应传递给queryMultiple函数。在t毫秒内不应连续调用queryMultiple。第一次调用getValue时,应立即使用该单个键调用queryMultiple。如果在t毫秒后再次调用了getValue,则所有传递的键应传递给queryMultiple,并返回最终结果。可以假设传递给该方法的每个键都是唯一的。
下图说明了节流算法的工作原理。每个矩形代表 100 毫秒。节流时间为 400 毫秒。
示例 1:
输入:
queryMultiple = async function (keys) { return keys.map((key) => key + '!'); }; t = 100; calls = [ { key: 'a', time: 10 }, { key: 'b', time: 20 }, { key: 'c', time: 30 } ];输出:
[ { resolved: 'a!', time: 10 }, { resolved: 'b!', time: 110 }, { resolved: 'c!', time: 110 } ];解释:
const batcher = new QueryBatcher(queryMultiple, 100); setTimeout(() => batcher.getValue('a'), 10); // "a!" at t=10ms setTimeout(() => batcher.getValue('b'), 20); // "b!" at t=110ms setTimeout(() => batcher.getValue('c'), 30); // "c!" at t=110msqueryMultiple 简单地给键添加了"!"。
在 t=10ms 时,调用 getValue('a'),立即调用 queryMultiple(['a']) 并立即返回结果。
在 t=20ms 时,调用 getValue('b'),但查询需要等待。
在 t=30ms 时,调用 getValue('c'),但查询需要等待。
在 t=110ms 时,调用 queryMultiple(['b', 'c']) 并立即返回结果。
示例 2;
输入:
queryMultiple = async function (keys) { await new Promise((res) => setTimeout(res, 100)); return keys.map((key) => key + '!'); }; t = 100; calls = [ { key: 'a', time: 10 }, { key: 'b', time: 20 }, { key: 'c', time: 30 } ];输出:
[ { resolved: 'a!', time: 110 }, { resolved: 'b!', time: 210 }, { resolved: 'c!', time: 210 } ];解释:
这个例子与示例 1 相同,只是在 queryMultiple 中有一个 100ms 的延迟。结果也相同,只是 promise 的解析时间延迟了 100ms。
示例 3:
输入:
queryMultiple = async function(keys) { await new Promise(res => setTimeout(res, keys.length * 100)); return keys.map(key => key + '!'); } t = 100 calls = [ {"key": "a", "time": 10}, {"key": "b", "time": 20}, {"key": "c", "time": 30}, {"key": "d", "time": 40}, {"key": "e", "time": 250} {"key": "f", "time": 300} ]输出:
[ { resolved: 'a!', time: 110 }, { resolved: 'e!', time: 350 }, { resolved: 'b!', time: 410 }, { resolved: 'c!', time: 410 }, { resolved: 'd!', time: 410 }, { resolved: 'f!', time: 450 } ];解释: 在 t=10ms 时,调用 queryMultiple(['a']) ,在 t=110ms 时解析。
在 t=110ms 时,调用 queryMultiple(['b', 'c', 'd']) ,在 t=410ms 时解析。
在 t=250ms 时,调用 queryMultiple(['e']) ,在 t=350ms 时解析。
在 t=350ms 时,调用 queryMultiple(['f']) ,在 t=450ms 时解析。
提示:
0 <= t <= 10000 <= calls.length <= 101 <= key.length <= 100- 所有的键值都是唯一的
解题思路
构造函数:初始化
queryMultiple函数和节流时间t,并创建一个批次(数组)来存储需要查询的键,以及另一个对象来存储每个键的 Promise 以便在批处理后解析结果。queue存储当前批次的键。promises记录每个键对应的 Promise,使每个调用者都能获取到查询结果。
批处理逻辑:
- 第一次调用
getValue时,立即触发查询。 - 接下来的调用在
t毫秒内只会添加到批次中,并等待批次到达延迟时间后再一起查询。 - 使用
setTimeout控制批次的间隔时间。
- 第一次调用
getValue 方法:
getValue接受一个键,返回与该键关联的值。- 如果该键是第一次出现,则创建一个 Promise,将它加入批处理队列
queue,并在批次执行后解析结果。 - 使用
clearTimeout和setTimeout来控制调用间隔。没有计时器时立即查询,有计时器则等待其到期。 - 当达到
t毫秒延迟时,将所有积累的键传递给queryMultiple,然后将对应的结果映射给各自的 Promise。
_triggerQuery 方法:
- 将
queue中的所有键批量查询,并将返回结果分配到相应的 Promise。 - 查询后清空
queue并重置计时器。
- 将
代码
class QueryBatcher {
constructor(queryMultiple, t) {
this.queryMultiple = queryMultiple;
this.t = t;
this.queue = []; // 存储需要查询的键
this.promises = {}; // 存储每个键的 Promise
this.timeout = null; // 用于控制批次的延迟
}
async getValue(key) {
// 如果该键是第一次出现,则初始化它的 Promise
if (!this.promises[key]) {
this.promises[key] = new Promise((resolve) => {
this.queue.push(key);
this.promises[key].resolve = resolve;
});
// 如果没有延迟计时器,则立即查询当前批次中的键
if (this.timeout === null) {
this._triggerQuery();
} else {
// 如果已设置延迟计时器,则等待当前计时器到期后再查询
clearTimeout(this.timeout);
this.timeout = setTimeout(() => this._triggerQuery(), this.t);
}
}
return this.promises[key];
}
// 执行批次查询并解析结果
async _triggerQuery() {
const keysToQuery = [...this.queue];
this.queue = []; // 清空当前队列
this.timeout = null; // 重置计时器
// 进行查询,并将结果分发给相应的 Promise
const results = await this.queryMultiple(keysToQuery);
keysToQuery.forEach((key, index) => {
this.promises[key].resolve(results[index]);
delete this.promises[key]; // 查询后删除该键的 Promise
});
}
}